key 01257721
{
"doctorId": 58,
"patientName": "Robyn Kirby",
"patientDob": "1986-05-16T19:01:52.4075881-04:00"
}
key 116wmq8i
{
"doctorId": 8,
"patientName": "Helen Clark",
"patientDob": "2016-02-01T04:54:30.3505879-05:00"
}Posts tagged with 'c'
This is a repost that originally appeared on the Couchbase Blog: Aggregate grouping with N1QL or with MapReduce.
Aggregate grouping is what I’m titling this blog post, but I don’t know if it’s the best name. Have you ever used MySQL’s GROUP_CONCAT function or the FOR XML PATH('') workaround in SQL Server? That’s basically what I’m writing about today. With Couchbase Server, the easiest way to do it is with N1QL’s ARRAY_AGG function, but you can also do it with an old school MapReduce View.
I’m writing this post because one of our solution engineers was working on this problem for a customer (who will go unnamed). Neither of us could find a blog post like this with the answer, so after we worked together to come up with a solution, I decided I would blog about it for my future self (which is pretty much the main reason I blog anything, really. The other reason is to find out if anyone else knows a better way).
Before we get started, I’ve made some material available if you want to follow along. The source code I used to generate the "patient" data used in this post is available on GitHub. If you aren’t .NET savvy, you can just use cbimport on sample data that I’ve created. (Or, you can use the N1QL sandbox, more information on that later). The rest of this blog post assumes you have a "patients" bucket with that sample data in it.
Requirements
I have a bucket of patient documents. Each patient has a single doctor. The patient document refers to a doctor by a field called doctorId. There may be other data in the patient document, but we’re mainly focused on the patient document’s key and the doctorId value. Some examples:
Next, we can assume that each doctor can have multiple patients. We can also assume that a doctor document exists, but we don’t actually need that for this tutorial, so let’s just focus on the patients for now.
Finally, what we want for our application (or report or whatever), is an aggregate grouping of the patients with their doctor. Each record would identify a doctor and a list/array/collection of patients. Something like:
| doctor | patients |
|---|---|
|
58 |
01257721, 450mkkri, 8g2mrze2 … |
|
8 |
05woknfk, 116wmq8i, 2t5yttqi … |
|
… etc … |
… etc … |
This might be useful for a dashboard showing all the patients assigned to doctors, for instance. How can we get the data in this form, with N1QL or with MapReduce?
N1QL Aggregate grouping
N1QL gives us the ARRAY_AGG function to make this possible.
Start by selecting the doctorId from each patient document, and the key to the patient document. Then, apply ARRAY_AGG to the patient document ID. Finally, group the results by the doctorId.
SELECT p.doctorId AS doctor, ARRAY_AGG(META(p).id) AS patients
FROM patients p
GROUP BY p.doctorId;Note: don’t forget to run CREATE PRIMARY INDEX ON patients for this tutorial to enable a primary index scan.
Imagine this query without the ARRAY_AGG. It would return one record for each patient. By adding the ARRAY_AGG and the GROUP BY, it now returns one record for each doctor.
Here’s a snippet of the results on the sample data set I created:
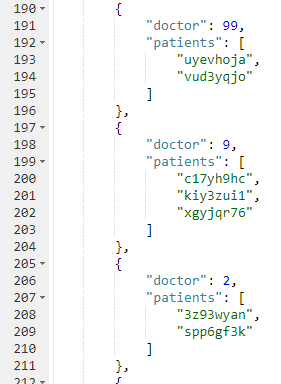
If you don’t want to go through the trouble of creating a bucket and importing sample data, you can also try this in the N1QL tutorial sandbox. There aren’t patient documents in there, so the query will be a little different.
I’m going to group up emails by age. Start by selecting the age from each document, and the email from each document. Then, apply ARRAY_AGG to the email. Finally, group the results by the age.
SELECT t.age AS age, ARRAY_AGG(t.email) AS emails
FROM tutorial t
group by t.age;Here’s a screenshot of some of the results from the sandbox:

Aggregate group with MapReduce
Similar aggregate grouping can also be achieved with a MapReduce View.
Start by creating a new View. From Couchbase Console, go to Indexes, then Views. Select the "patients" bucket. Click "Create Development View". Name a design document (I called mine "_design/dev_patient". Create a view, I called mine "doctorPatientGroup".
We’ll need both a Map and a custom Reduce function.
First, for the map, we just want the doctorId (in an array, since we’ll be using grouping) and the patient’s document ID.
function (doc, meta) {
emit([doc.doctorId], meta.id);
}Next, for the reduce function, we’ll take the values and concatenate them into an array. Below is one way that you can do it. I do not claim to be a JavaScript expert or a MapReduce expert, so there might be a more efficient way to tackle this:
function reduce(key, values, rereduce) {
var merged = [].concat.apply([], values);
return merged;
}After you’ve created both map and reduce functions, save the index.
Finally, when actually calling this Index, set group_level to 1. You can do this in the UI:
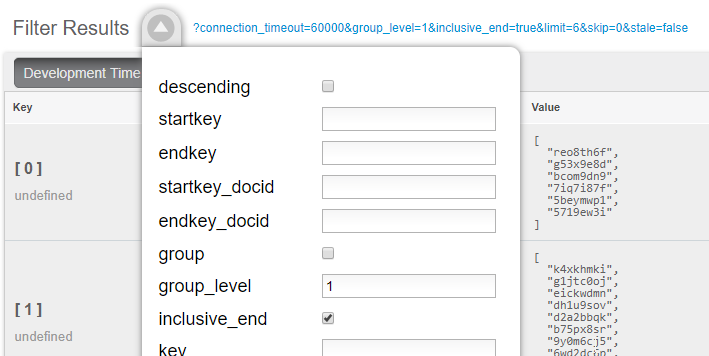
Or you can do it from the Index URL. Here’s an example from a cluster running on my local machine:
http://127.0.0.1:8092/patients/_design/dev_patients/_view/doctorPatientGroup?connection_timeout=60000&full_set=true&group_level=1&inclusive_end=true&skip=0&stale=falseThe result of that view should look like this (truncated to look nicer in a blog post):
{"rows":[
{"key":[0],"value":["reo8th6f","g53x9e8d", ... ]},
{"key":[1],"value":["k4xkhmki","g1jtc0oj", ... ]},
{"key":[2],"value":["spp6gf3k","3z93wyan"]},
{"key":[3],"value":["qnx93fh3","gssusiun", ...]},
{"key":[4],"value":["qvqgb0ve","jm0g69zz", ...]},
{"key":[5],"value":["ywjfvad6","so4uznxx", ...]}
...
]}Summary
I think the N1QL method is easier, but there may be performance benefits to using MapReduce in some cases. In either case, you can accomplish aggregate grouping just as easily (if not more easily) as in a relational database.
Interested in learning more about N1QL? Be sure to check out the complete N1QL tutorial/sandbox. Interested in MapReduce Views? Check out the MapReduce Views documentation to get started.
Did you find this post useful? Have suggestions for improvement? Please leave a comment below, or contact me on Twitter @mgroves.

Jeremy Clark is writing unit tests.
Show Notes:
- David Neal was a guest on the podcast, episode 010
- Regression tests - Change Code Without Fear
- Code coverage (NCover is a tool that reports on code coverage for .NET code)
- TDD and BDD and ATDD
- WPF and XML, MVVM
- Book: The Art of Unit Testing, by Roy Osherove
- Jeremy's website, Jeremy Bytes
- Jeremy Clark on Pluralsight
- Jeremy Clark on YouTube
Want to be on the next episode? You can! All you need is the willingness to talk about something technical.
Theme music is "Crosscutting Concerns" by The Dirty Truckers, check out their music on Amazon or iTunes.
This is a repost that originally appeared on the Couchbase Blog: Azure: Getting Started is Easy and Free.
Azure is where Microsoft is spending a lot of its efforts lately. Microsoft is dedicated to making Azure a success. As someone who started working with Azure a little in the early days, I can say that it’s come a long way, and offers a remarkable set of services at good prices.
But not everyone is on board with Azure or even with cloud computing yet. If you haven’t yet dipped your toe into the Azure pool, but are curious, this blog post is for you.
What is cloud computing? What is Azure?
Cloud computing basically means that instead of running applications in your own data center, you run it in someone else’s data center. Why would I do that?
Running a data center is difficult and expensive. You have to purchase hardware, manage upgrades, security, networking, and even stuff like electricity, ventilation, and cooling. For some enterprises, this is either not a big deal or it’s worth the hassle. But for many enterprises, the value that you’re delivering is not in the hardware or the operating system and so on, but in the domain expertise that goes into the software you’re building. Then, cloud appeals to enterprises who would rather someone else handle all that other stuff.
A metaphor that I really like was written up by Albert Barron in a blog post called Pizza as a Service (I especially like the diagram). It makes sense for a pizza company to control the whole stack because pizza making is their core competency. But if pizza making isn’t your job, it makes sense to take another option, like dining out, so you can instead spend your time focusing on what you do best.
This isn’t to say that cloud is always the best solution, but it explains why many companies are choosing to move at least some of their infrastructure and platform to a cloud provider like Microsoft’s Azure.
How do I sign up for Azure?
If you’re on the fence, I recommend at least giving it a try, so that you’re prepared for the day that your CTO comes to you and asks "so what are we doing about the cloud?"
Signing up for Azure is easy.
Create Microsoft account
To start, you’ll need a Microsoft account. If you don’t already have one, you can signup here. It’s free, and you can use it in a bunch of other places later, even if you end up not liking Azure.
Create Azure account
Next, go to azure.microsoft.com and create a free account. Signing up with that link will give you $200 in free credit to use on Azure services. You do need to use a credit card to sign up, but it is just for verifying your identity (they don’t want a bunch of spammers and bitcoin bots). Microsoft will not charge you until you say so.
Side note: If you have an MSDN/Visual Studio license, are part of the BizSpark program or have an educational grant through AzureU (ask your professor!), you may already have some free Azure credit on a monthly basis!
Speaking of money, there are some things you can do in Azure that are absolutely free. But, running Couchbase Server currently requires you to provision Virtual Machines, so if you want to play with Couchbase, you will put that $200 to good use.
Couchbase and Azure: Is $200 enough?
When I first started with Azure, I was very worried that I’d run up a big tab if I wasn’t careful. With the $200 trial, you won’t get charged until you explicitly tell Microsoft to do so. But years later, after my initial trial, I’ve still never had a problem of an unexpectedly high bill.
Quotas
I’ve never had this problem because:
a) Azure services are very reasonably priced, and
b) Microsoft makes it hard to hop on a runaway train of spending money.
In fact, almost a year ago, I was tasked with provisioning a medium-sized cluster of Couchbase nodes on some very beefy Virtual Machines. Lots of RAM, lots of processor cores, 10 total virtual machines all running Couchbase. I started doing this (manually, to begin with) and discovered that Azure actually has a quota that limits the number of cores you can provision. If you want to create a huge Couchbase cluster, you’ll first need to request an increase in the limit on the number of cores and/or virtual machines that you are allowed to have (this is a manual process, again to avoid abuse/surprises/exploitation/etc).
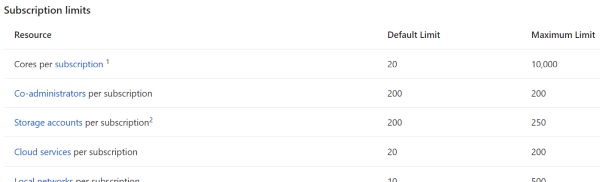
Because of that, I realized that even if I had created an experimental automated script that I accidentally asked to create 100 machines instead of 10, Azure would stop me.
It cost how much?
Until you want to build that huge cluster, you probably won’t need more than $200 to start with, and you won’t need to increase your quota.
As an example, I ran a single-node Couchbase Server on a low-end virtual machine within the last 30 days. I must have provisioned, used it, and tore it down 3 or 4 times. As you can see from the below screenshot of my billing statement, it cost me a grand total of $0.11 for an hour and a half of VM time (and I think there are a few pennies for related services, not shown).
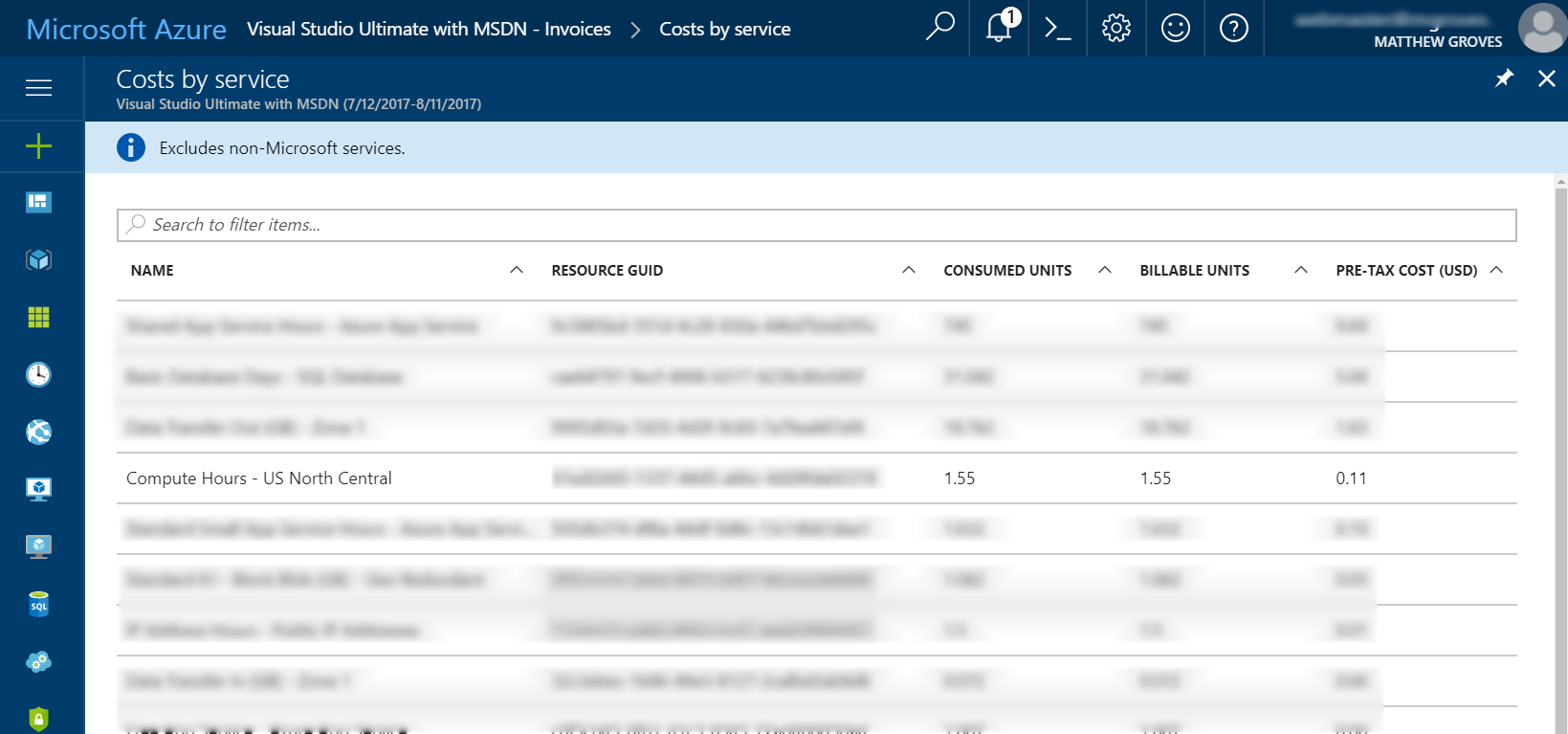
(Some information blurred to protect the innocent).
Your mileage will vary, but my point is that I think you will find it more challenging to use up that $200 credit than you think.
More than enough to get started with Couchbase
Finally, when you’re ready to play around with Couchbase, I encourage you to check out other blog posts about Couchbase Server.
Also, watch this short instructional video on how to provision Couchbase Server clusters automatically. You don’t have to provision a Virtual Machine, install Couchbase, do the initial cluster setup, network them together, etc manually. This video (courtesy of Ben Lackey from the Couchbase Partners team) shows you how to provision a Couchbase Server cluster from the Azure Marketplace.
Summary
If you’ve never used Azure or any cloud computing, now is your chance to get started. I’d love to hear about your experiences with Azure, with Couchbase, and your overall impressions of cloud computing. Please leave a comment below, or talk to me on Twitter @mgroves.

James Bender has opinions about JavaScript frameworks.
Show Notes:
- jQuery
- AngularJS
- Angular (aka Angular 2, Angular 4, Angular.io)
- Blast from the past: ASP.NET User Controls
- React
- Aurelia (my current favorite)
- Vue
- Aurelia introduction by Rob Eisenberg
- TypeScript
- Bender's TDD book: Professional Test Driven Development with C#: Developing Real World Applications with TDD
- Bender's upcoming new book: Developing SPAs: Working with Visual Studio, Angular, and ASP.NET Web API
- Jest
Want to be on the next episode? You can! All you need is the willingness to talk about something technical.
Theme music is "Crosscutting Concerns" by The Dirty Truckers, check out their music on Amazon or iTunes.
This is a repost that originally appeared on the Couchbase Blog: Azure Functions with Couchbase Server.
Azure Functions are Microsoft’s answer to Amazon’s Lambdas or Google’s Cloud Functions (aka "serverless" architecture). They give you a way to deploy small pieces of code, and let Azure handle the underlying server. I’ve never used them before, so I thought I would give them a try beyond "Hello, World", by getting them to work with Couchbase Server.
There are more options in Azure Functions beyond simple HTTP events (e.g. Blob triggers, GitHub webhooks, Azure Storage queue triggers, etc). But, for this blog post, I’m going to focus on just HTTP events. I’ll create simple "Get" and "Set" endpoints that interact with Couchbase Server.
Before beginning, you can follow along by getting the source code for this blog post on GitHub.
Also, please read the Azure Functions and Lazy Initialization with Couchbase Server post. It contains an important update about using Couchbase Server and Azure Functions.
Getting setup to develop Azure Functions
For this blog post, I decided to try Visual Studio Preview.

I did this because there is a handy tool for creating Azure Function projects in Visual Studio.

But it only works for the preview version at this time. You don’t have to use these tools to develop Azure Functions, but it made the process simpler for me.
Once I had this tooling in place, all I had to was to File→New→Project. Then under "Cloud", select "Azure Functions".
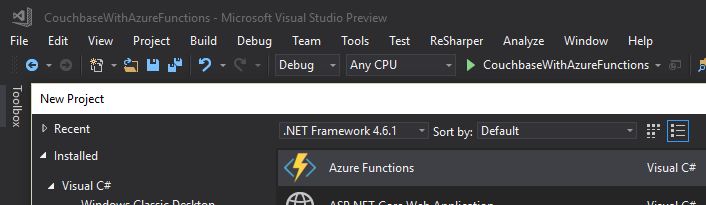
Once you do this, you’ll have an empty looking project with a couple of JSON files. Right click on the project, add item, and select "Azure Function".
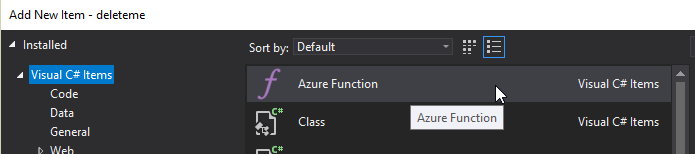
Next, you’ll need to select what kind of Azure Function you want to create. I chose "HttpTrigger". I also chose "Anonymous" to keep this post simple, but depending on your use case, you may want to require an authentication token. After you do this, a very simple shell of a function will be generated (as a C# class). You can execute this function locally (indeed, that is what the local.settings.json file is for) so you can test it out without deploying to Azure yet.
Writing a "Get" function
First, I decided that I wanted two Azure Functions: one to "get" a piece of data by ID, and one to "set" a new piece of given data. I started by defining the shape of my data with a simple C# POCO:
public class MyDocument
{
public string Name { get; set; }
public int ShoeSize { get; set; }
public decimal Balance { get; set; }
}Here is the Azure function that I wrote to "get" that document from Couchbase Server:
public static async Task<HttpResponseMessage> Get([HttpTrigger(AuthorizationLevel.Anonymous, "get", Route = null)]HttpRequestMessage req, TraceWriter log)
{
// parse query parameter
var id = req.GetQueryNameValuePairs()
.FirstOrDefault(q => string.Compare(q.Key, "id", true) == 0)
.Value;
using (var cluster = GetCluster())
{
using (var bucket = GetBucket(cluster))
{
var doc = await bucket.GetAsync<MyDocument>(id);
return req.CreateResponse(HttpStatusCode.OK, doc.Value, new JsonMediaTypeFormatter());
}
}
}Some things to note:
-
I remove the
"post"that was generated by the tooling, since I want this to only be a"get"function. -
Parsing the query parameter seems like a lot of extra code for this simple case. You can alternatively create a "function with parameters"
-
GetClusterandGetBucketwill be discussed later in this post. But the short story is that I want this code to work both locally and deployed to Azure
Next, run this function locally, and you’ll get a console screen that looks similar to this:
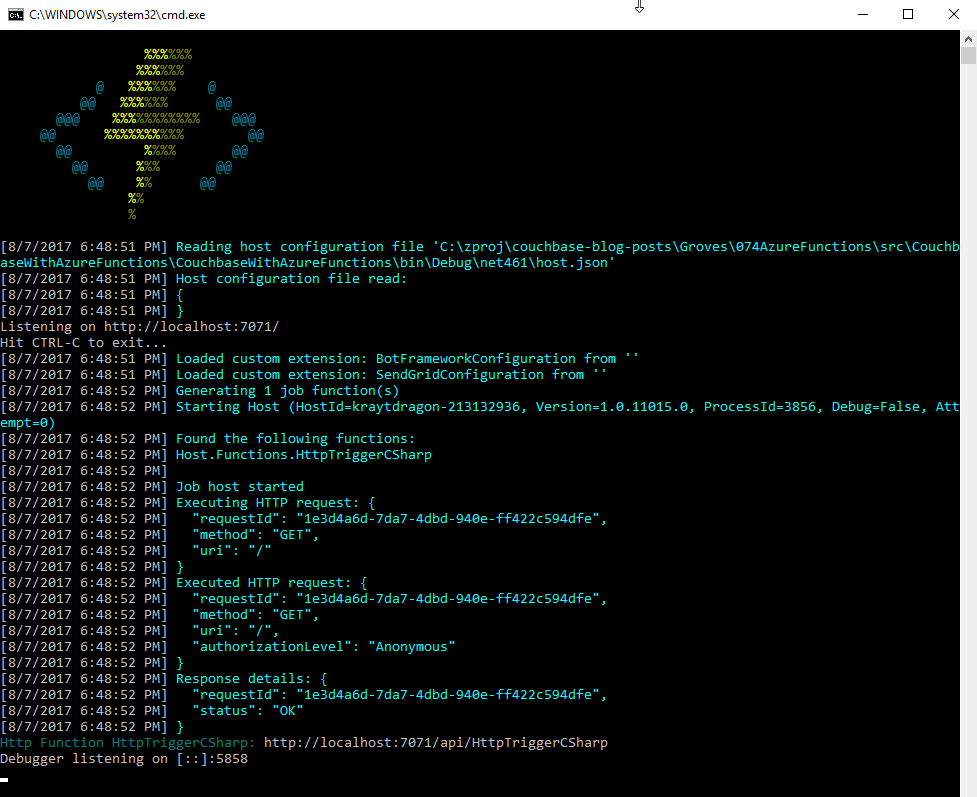
At the bottom, you’ll notice that it tells you the Azure Function URL(s). Assuming I had a document in Couchbase (I don’t yet), I could create an HTTP request with a tool like Postman to: http://localhost:7071/api/HttpTriggerCsharpGet?id=123456
Currently, if I do that, I’ll get "null" as a response (since I don’t have any validation or error checking code). So let’s move on and create a "Set" function.
Writing a "Set" function
The "Set" function will be slightly different. I want document information POSTed to it, and I want it to return a message like "New document inserted with ID 123456".
public static async Task<HttpResponseMessage> Set([HttpTrigger(AuthorizationLevel.Anonymous, "post", Route = null)] MyDocument req, TraceWriter log)
{
var id = Guid.NewGuid().ToString();
using (var cluster = GetCluster())
{
using (var bucket = GetBucket(cluster))
{
await bucket.InsertAsync(id, req);
}
}
return new HttpResponseMessage
{
Content = new StringContent($"New document inserted with ID {id}"),
StatusCode = HttpStatusCode.OK
};
}This function has a similar shape to the Get, but some important things to note:
-
There is only
"post"in the HttpTrigger attribute. -
Instead of
HttpRequestMessageas the first parameter, I’ve decided to useMyDocument, and let Azure Functions do the binding for me. -
Since I don’t have
HttpRequestMessage, I can’t call itsCreateResponsemethod, so instead I instantiate a newHttpResponseMessagedirectly to return the success message at the end.
To create a request in Postman, I’ll use a URL of http://localhost:7071/api/HttpTriggerCsharpSet. In the headers, I’ll set Content-Type to "application/json". Finally, the body will be JSON:
{
"Name": "matthew",
"Balance": 107.18,
"ShoeSize": 14
}Now, when I POST that to the endpoint, I’ll get a response message of "New document inserted with ID f05ea97e-7c2f-4f88-b72d-19756f6a6f35".
Connecting to Couchbase Server
I have glossed over how these functions connect to Couchbase Server.
Previously, I mentioned two methods, GetCluster and GetBucket that will connect to the cluster and bucket, respectively.
private static Cluster GetCluster()
{
var uri = ConfigurationManager.AppSettings["couchbaseUri"];
return new Cluster(new ClientConfiguration
{
Servers = new List<Uri> { new Uri(uri) }
});
}
private static IBucket GetBucket(Cluster cluster)
{
var bucketName = ConfigurationManager.AppSettings["couchbaseBucketName"];
var bucketPassword = ConfigurationManager.AppSettings["couchbaseBucketPassword"];
return cluster.OpenBucket(bucketName, bucketPassword);
}At this point, most of this code should be familiar if you’ve used Couchbase Server and the Couchbase .NET SDK before. I’m connecting to a single node cluster, and then connecting a bucket that has a password set (I’m using Couchbase Server 4.6).
But, the important thing to point out here is the use of Configuration.AppSettings. In the local.settings.json file, I’ve added these Couchbase settings to the Value section:
{
"IsEncrypted": false,
"Values": {
"AzureWebJobsStorage": "",
"AzureWebJobsDashboard": "",
"couchbaseUri": "http://localhost:8091",
"couchbaseBucketName": "azurefunctions",
"couchbaseBucketPassword": "Password88!"
}
}When running Azure Functions locally, this file is used for configuration. I have Couchbase Server running locally with a bucket called "azurefunctions". Anything in "Values" can be accessed via Configuration.AppSettings.
Deploying to Azure
Before deploying the Azure Functions, I’ll need to create a Couchbase Cluster on Azure. This is very easy to do, thanks to Ben Lackey’s great work on the Azure Marketplace. Once that’s deployed, deploying the Azure Functions are also easy, thanks to Visual Studio.
Deploying Couchbase Server to Azure
Here is a short video walking you through the process of creating a Couchbase Server cluster on Azure.
For my example, I followed that video closely. Here is step 1, where I configure the username, password, and resource group.
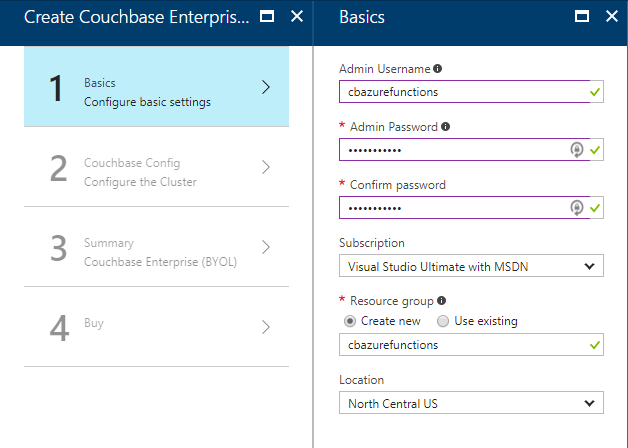
For the second step, I only created a single node cluster on the smallest, cheapest VM (DS1 v2). I created 0 Sync Gateway nodes, since I’m not using Sync Gateway for this example.
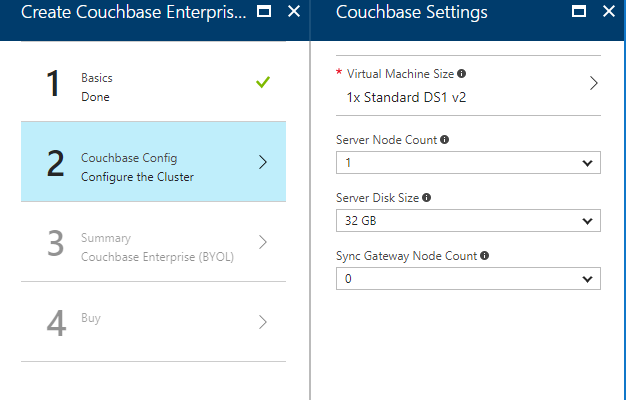
Step 3 is just a summary, and step 4 is a confirmation. It will take 3-5 minutes for the Couchbase Cluster to start up in Azure.
Once the cluster is created, find the URL for the first node in the cluster (just as demonstrated in the above video). My URL looked something like: http://vm0.server-hsmkrefstzg2t.northcentralus.cloudapp.azure.com:8091. Go to this URL, login, and create a bucket (I called mine "azurefunctions", just like I did locally).
Deploying Azure Functions to Azure
Now, Couchbase Server is running. So let’s deploy the Azure Functions that will interact with it.
To begin, right-click the project in Visual Studio and select "publish". You’ll need to create a new publish profile the first time you do this, but that’s easy.
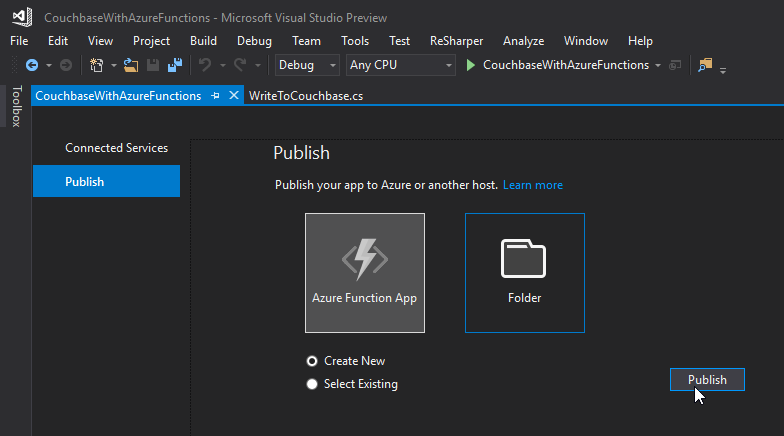
Give your functions an app name, select a subscription, select a resource group (you can create a new one, or use the same group that you created above for Couchbase), select a service plan, and finally a storage account. You can create new ones when necessary.
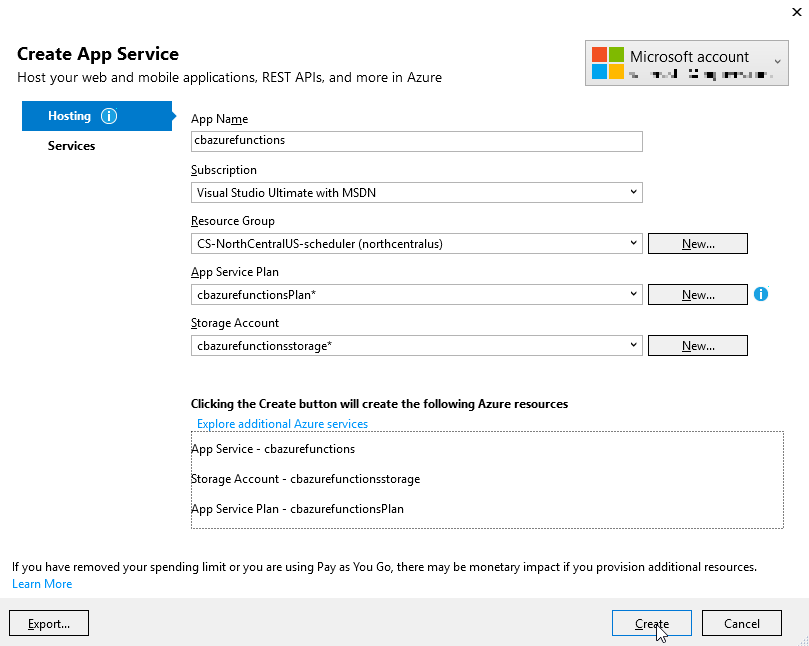
Click "create" and these items will start to be created in Azure (it may take a minute or two).
Trying out the Azure Functions
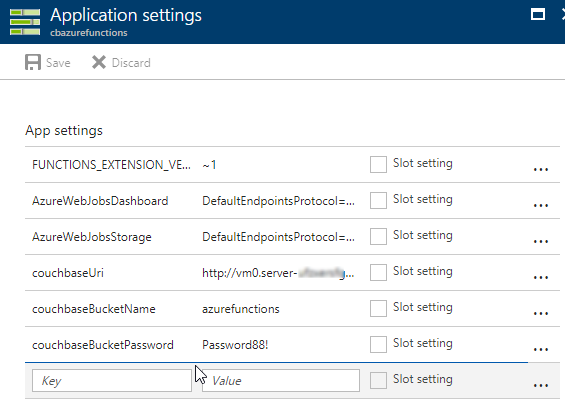
Finally, remember that the Azure Functions need to know the URI, bucket name, and password in order to connect to Couchbase Server. That information is in local.settings.json, but that file is not used for actual Azure deployments.
In the Azure portal, navigate to the Azure function (I called mine cbazurefunctions), and then select "Application Settings". Under "App settings", enter those three settings: couchbaseUri, couchbaseBucketName, and couchbaseBucketPassword.
Now, repeat the Postman process mentioned above to try out the Azure functions and make sure they work. Your URL will vary, but mine was http://cbazurefunctions.azurewebsites.net/.
Summary
This is my first time trying out Azure Functions. This blog post shows a simple demo, but there are other factors to consider before you start using this in production:
-
Authentication - I used anonymous Azure Functions to keep it simple. Azure Functions can also provide authentication tokens to use that prevent access except to authorized users.
-
App settings - Setting them manually in the portal may not be the best solution. There is probably a way to automate that portion, and that’s something I’ll look into in the future.
-
HTTPS/TLS - You will likely want to have some level of encryption as you are getting and posting data to your Azure Functions. The above example transmits everything in clear text.
Anything I missed? Any more tips or suggestions to share to make this process easier or better? Please leave a comment below or ping me on Twitter @mgroves.
