[Migration(1)]
public class Migration001_CreateInitialScopeAndCollection : Migrate
{
public override void Up()
{
Create.Scope("myScope")
.WithCollection("myCollection1");
}
public override void Down()
{
Delete.Scope("myScope");
}
}Posts tagged with 'sql'
This blog post is a part of the 2022 C# Advent. Every day of Advent, two contributions from C# enthusiasts are revealed. Thanks for reading, and Merry Christmas!
I’ve written about How I use Fluent Migrator and Lessons learned about Fluent Migrator. I like using Fluent Migrator when I worked with relational databases.
However, I spend most of my time working with the NoSQL document database Couchbase, these days. If the idea of Fluent Migrator for Couchbase sounds interesting, read on!
What are database migrations?
Database migrations (not to be confused with data migrations) are a series of scripts/definitions that build the structure of a database. For instance, the first script could create 15 tables. The next script might alter a table, or add a 16th table. And so on.
Why are they important?
Having database migrations are important because they make sure anyone interacting with the database is on the same page, whether they’re working on a local database, test database, staging database, production, etc. Migrations can be part of the CI/CD process, as well.
What good is that for NoSQL?
If you’re not familiar with NoSQL, you might think that migrations wouldn’t make any sense. However, NoSQL databases (especially document databases), while flexible, are not devoid of structure. For instance, in place of Database/Schema/Table/Row, Couchbase has the concepts of Bucket/Scope/Collection/Document that roughly correspond.
It’s true that a NoSQL migration would not have as much predefined detail (there’s nowhere to specify column names and data types, for instance), but the benefits of migrations can still help developers working with Couchbase.
Introducing NoSqlMigrator for Couchbase
I’ve created a brand new project called NoSqlMigrator, to offer the same style of migration as Fluent Migrator.
Important notes:
-
This is not a fork or plugin of Fluent Migrator. It’s a completely separate project.
-
This is not an official Couchbase, Inc product. It’s just me creating it as an open source, community project.
-
It’s very much a WIP/alpha release. Please leave suggestions, criticisms, PRs, and issues!
Setting up migrations in C#
The process is very similar to Fluent Migrator.
-
Create a project that will contain your migration classes (you technically don’t have to, but I recommend it).
-
Add NoSqlMigrator from NuGet to that project.
-
Create classes that inherit from
Migratebase class. Define anUpandDown. Add aMigrationattribute and give it a number (typically sequential). -
When you’re ready to run migrations, you can use the CLI migration runner, available as a release on GitHub, or you can use the
MigrationRunnerclass, and run the migrations from whatever code you like. (I recommend the CLI).
Currently, NoSqlMigrator only supports Couchbase. Unlike the relational world, there is a lot of variance in structure and naming in the NoSQL world, so adding support for other NoSQL databases might be awkward (But I won’t rule that out for the far future).
Creating your first migration
Here’s an example of a migration that creates a scope and a collection (a bucket must already exist) when going "Up". When going down, the scope is deleted (along with any collections in it).
If you are new to migrations, the Down can sometimes be tricky. Not everything can be neatly "downed". However, I find that I tend to only use Down during development, and rarely does it execute in test/integration/production. But it is possible, so do your best when writing Down, but don’t sweat it if you can’t get it perfect.
Running the migration
Here’s an example of using the command line to run a migration:
> NoSqlMigrator.Runner.exe MyMigrations.dll couchbase://localhost Administrator password myBucketNameThat will run all the Up implementations (that haven’t already been run: it keeps track with a special document in Couchbase).
You can also specify a limit (e.g. run all migrations up to/down from #5) and you can specify a direction (up/down). Here’s an example of running Up (explicitly) with a limit of 5:
> NoSqlMigrator.Runner.exe MyMigrations.dll couchbase://localhost Administrator password myBucketName -l 5 -d UpMore features for NoSQL migrations
Here are all the commands currently available:
-
Create.Scope
-
Create.Collection
-
Create.Index
-
Delete.Scope
-
Delete.Collection
-
Delete.FromCollection
-
Delete.Index
-
Insert.IntoCollection
-
Execute.Sql
-
Update.Document
-
Update.Collection
I’m working on a few more, and I have some GitHub issues listing commands that I plan to add. But if you can think of any others, please create an issue!
Tips and Conclusion
Many of the Lessons learned still apply to NoSqlMigrator.
In that post, I mention Octopus, but imagine any CI/CD/deployment tool of your choice in its place (e.g. Jenkins, GitHub Actions, etc).
I think NoSqlMigrator can be a very handy tool for keeping databases in sync with your team, checking knowledge into source control, and providing a quick way to get a minimum database structure built, to make your day of coding a little easier.
Please give it a try in your own project! If you’ve not used Couchbase, check out a free trial of Couchbase Capella DBaaS.

Jeffrey Miller is using Neo4j. This episode is sponsored by Smartsheet.
Show Notes:
-
CosmosDB on Azure
-
Magic: The Gathering is a collectible card game that I once sunk a lot of money into
-
Michael Hunger developer relations with Neo4j
-
link: Presentation slides by Jeffrey
Want to be on the next episode? You can! All you need is the willingness to talk about something technical.
Music is by Joe Ferg, check out more music on JoeFerg.com!
This is a repost that originally appeared on the Couchbase Blog: New Querying Features in Couchbase Server 5.5.
New querying features figure prominently in the latest release of Couchbase Server 5.5. Check out the announcement and download the developer build for free right now.
In this post, I want to highlight a few of the new features and show you how to get started using them:
-
ANSI JOINs - N1QL in Couchbase already has JOIN, but now JOIN is more standards compliant and more flexible.
-
HASH joins - Performance on certain types of joins can be improved with a HASH join (in Enterprise Edition only)
-
Aggregate pushdowns - GROUP BY can be pushed down to the indexer, improving aggregation performance (in Enterprise Edition only)
All the examples in this post use the "travel-sample" bucket that comes with Couchbase.
ANSI JOINs
Until Couchbase Server 5.5, JOINs were possible, with two caveats:
-
One side of the JOIN has to be document key(s)
-
You must use the
ON KEYSsyntax
In Couchbase Server 5.5, it is no longer necessary to use ON KEYS, and so writing joins becomes much more natural and more in line with other SQL dialects.
Previous JOIN syntax
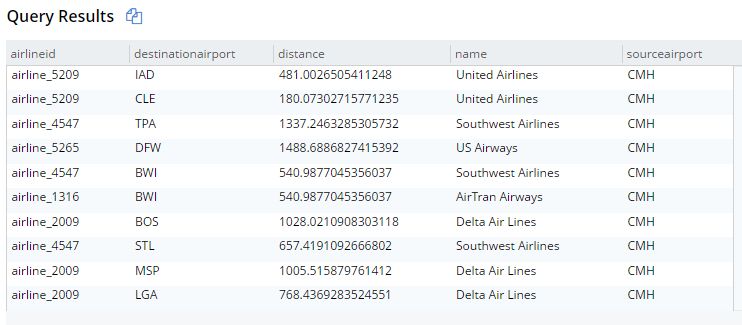
For example, here’s the old syntax:
SELECT r.destinationairport, r.sourceairport, r.distance, r.airlineid, a.name
FROM `travel-sample` r
JOIN `travel-sample` a ON KEYS r.airlineid
WHERE r.type = 'route'
AND r.sourceairport = 'CMH'
ORDER BY r.distance DESC
LIMIT 10;This will get 10 routes that start at CMH airport, joined with their corresponding airline documents. The result are below (I’m showing them in table view, but it’s still JSON):
New JOIN syntax
And here’s the new syntax doing the same thing:
SELECT r.destinationairport, r.sourceairport, r.distance, r.airlineid, a.name
FROM `travel-sample` r
JOIN `travel-sample` a ON META(a).id = r.airlineid
WHERE r.type = 'route'
AND r.sourceairport = 'CMH'
ORDER BY r.distance DESC
LIMIT 10;The only difference is the ON. Instead of ON KEYS, it’s now ON <field1> = <field2>. It’s more natural for those coming from a relational background (like myself).
But that’s not all. Now you are no longer limited to joining just on document keys. Here’s an example of a JOIN on a city field.
SELECT a.airportname, a.city AS airportCity, h.name AS hotelName, h.city AS hotelCity, h.address AS hotelAddress
FROM `travel-sample` a
INNER JOIN `travel-sample` h ON h.city = a.city
WHERE a.type = 'airport'
AND h.type = 'hotel'
LIMIT 10;This query will show hotels that match airports based on their city.
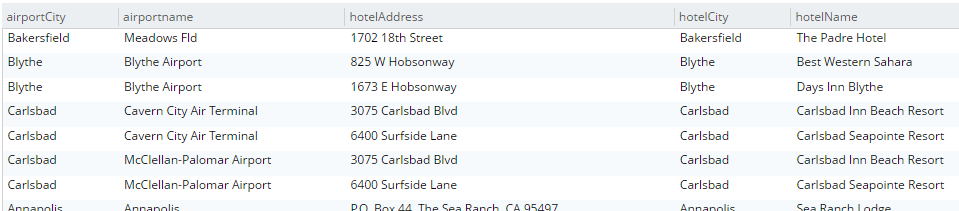
Note that for this to work, you must have an index created on the field that’s on the inner side of the JOIN. The "travel-sample" bucket already contains a predefined index on the city field. If I were to attempt it with other fields, I’d get an error message like "No index available for ANSI join term…".
For more information on ANSI JOIN, check out the full N1QL JOIN documentation.
Note: The old JOIN, ON KEYS syntax will still work, so don’t worry about having to update your old code.
Hash Joins
Under the covers, there are different ways that joins can be carried out. If you run the query above, Couchbase will use a Nested Loop (NL) approach to execute the join. However, you can also instruct Couchbase to use a hash join instead. A hash join can sometimes be more performant than a nested loop. Additionally, a hash join isn’t dependent on an index. It is, however, dependent on the join being an equality join only.
For instance, in "travel-sample", I could join landmarks to hotels on their email fields. This may not be the best find to find out if a hotel is a landmark, but since email is not indexed by default, it illustrates the point.
SELECT l.name AS landmarkName, h.name AS hotelName, l.email AS landmarkEmail, h.email AS hotelEmail
FROM `travel-sample` l
INNER JOIN `travel-sample` h ON h.email = l.email
WHERE l.type = 'landmark'
AND h.type = 'hotel';The above query will take a very long time to run, and probably time out.
Syntax
Next I’ll try a hash join, which must be explicitly invoked with a USE HASH hint.
SELECT l.name AS landmarkName, h.name AS hotelName, l.email AS landmarkEmail, h.email AS hotelEmail
FROM `travel-sample` l
INNER JOIN `travel-sample` h USE HASH(BUILD) ON h.email = l.email
WHERE l.type = 'landmark'
AND h.type = 'hotel';A hash join has two sides: a BUILD and a PROBE. The BUILD side of the join will be used to create an in-memory hash table. The PROBE side will use that table to find matches and perform the join. Typically, this means you want the BUILD side to be used on the smaller of the two sets. However, you can only supply one hash hint, and only to the right side of the join. So if you specify BUILD on the right side, then you are implicitly using PROBE on the left side (and vice versa).
BUILD and PROBE
So why did I use HASH(BUILD)?
I know from using INFER and/or Bucket Insights that landmarks make up roughly 10% of the data, and hotels make up about 3%. Also, I know from just trying it out that HASH(BUILD) was slightly slower. But in either case, the query execution time was milliseconds. Turns out there are two hotel-landmark pairs with the same email address.
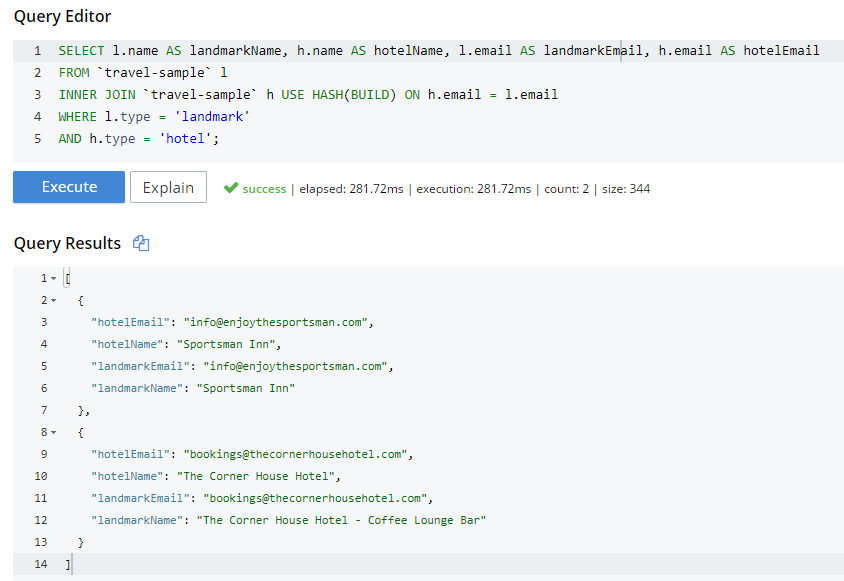
USE HASH will tell Couchbase to attempt a hash join. If it cannot do so (or if you are using Couchbase Server Community Edition), it will fall back to a nested-loop. (By the way, you can explicitly specify nested-loop with the USE NL syntax, but currently there is no reason to do so).
For more information, check out the HASH join areas of the documentation.
Aggregate pushdowns
Aggregations in the past have been tricky when it comes to performance. With Couchbase Server 5.5, aggregate pushdowns are now supported for SUM, COUNT, MIN, MAX, and AVG.
In earlier versions of Couchbase, indexing was not used for statements involving GROUP BY. This could severely impact performance, because there is an extra "grouping" step that has to take place. In Couchbase Server 5.5, the index service can do the grouping/aggregation.
Example
Here’s an example query that finds the total number of hotels, and groups them by country, state, and city.
SELECT country, state, city, COUNT(1) AS total
FROM `travel-sample`
WHERE type = 'hotel' and country is not null
GROUP BY country, state, city
ORDER BY COUNT(1) DESC;The query will execute, and it will return as a result:
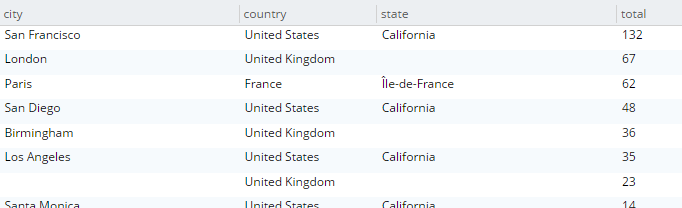
Let’s take a look at the visual query plan (only available in Enterprise Edition, but you can view the raw Plan Text in Community Edition).

Note that the only index being used is for the type field. The grouping step is doing the aggregation work. With the relatively small travel-sample data set, this query is taking around ~90ms on my single node desktop. But let’s see what happens if I add an index on the fields that I’m grouping by:
Indexing
CREATE INDEX ix_hotelregions ON `travel-sample` (country, state, city) WHERE type='hotel';Now, execute the above SELECT query again. It should return the same results. But:
-
It’s now taking ~7ms on my single node desktop. We’re taking ms, but with a large, more realistic data set, that is a huge difference in magnitude.
-
The query plan is different.

Note that this time, there is no 'group' step. All the work is being pushed down to the index service, which can use the ix_hotelregions index. It can use this index because my query is exactly matching the fields in the index.
Index push down does not always happen: your query has to meet specific conditions. For more information, check out the GROUP BY and Aggregate Performance areas of the documentation.
Summary
With Couchbase Server 5.5, N1QL includes even more standards-compliant syntax and becomes more performant than ever.
Try out N1QL today. You can install Enterprise Edition or try out N1QL right in your browser.
Have a question for me? I’m on Twitter @mgroves. You can also check out @N1QL on Twitter. The N1QL Forum is a good place to go if you have in-depth questions about N1QL.
This is a repost that originally appeared on the Couchbase Blog: Proof of Concept: Making a case to move from relational.
Proof of concept may be just what you need to start when you’re evaluating Couchbase.
We’ve been blogging a lot about the technical side of moving from a relational database like Oracle or SQL Server to Couchbase. Here are some of the resources and posts we’ve published:
But for this post, we’re going to talk more about the overall process instead of the technical details. You’ll see five steps to creating a successful proof of concept. And if you ever need help getting started, you can talk to a Couchbase Solutions Engineer.
Proof of Concept steps
These steps are not just for migrating an existing application to Couchbase, they also work just as well for creating a brand new "greenfield" application with Couchbase, or even augmenting an existing database (as opposed to replacing it completely).
When creating a Proof of Concept, it’s a good idea to keep the scope as small and simple as possible. Some questions to ask:
-
Will it prove/disprove what you need it to, and help you move to the next step?
-
Can this be accomplished fairly quickly? If it takes too long or isn’t a priority, it might fizzle out.
-
Ask a Couchbase technical team member: is this a good fit for Couchbase? You can draw on their experience to save yourself some heartburn.
Select a use case and application
When I talk to people about Couchbase and NoSQL, I tell them the only thing worse than not using Couchbase is using Couchbase for the wrong thing and becoming soured on document databases.
"Different isn't always better, but better is always different." - Author Unknown
— Programming Wisdom (@CodeWisdom) May 16, 2017
The benefits of a distributed database like Couchbase are:
-
Better performance
-
Better scalability
-
Higher availability
-
Greater data agility/flexibility
-
Improved operational management
If your application can benefit from one of those characteristics, it’s worth checking out Couchbase. Couchbase may not be the best fit if you need multi-document transactions. But as I showed in my post on data modeling, if you can nest data instead of scattering it in pieces, you may not need multi-document transactions as much as you think.
Further, conversations with Couchbase customers have lead us to identify the need beyond a traditional database to power interactions. Marriott calls this the "look-to-book" ratio.
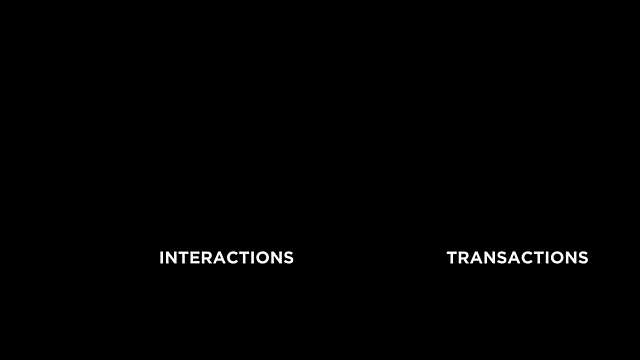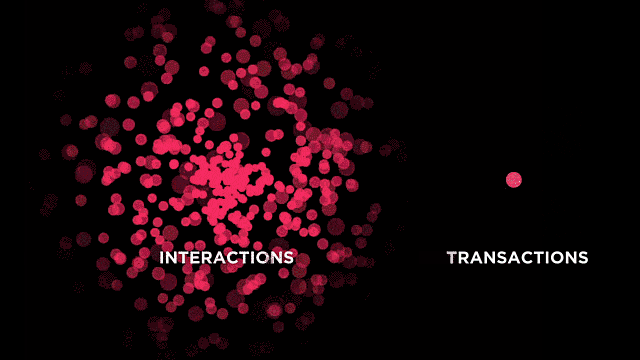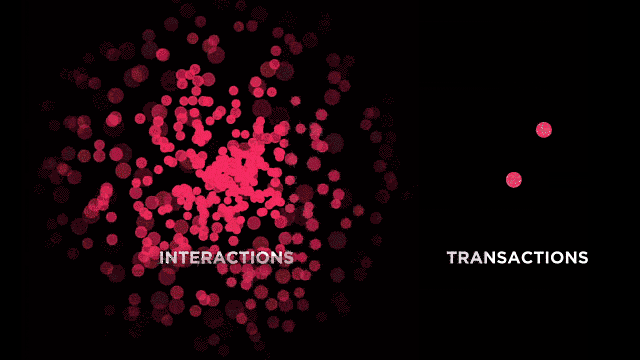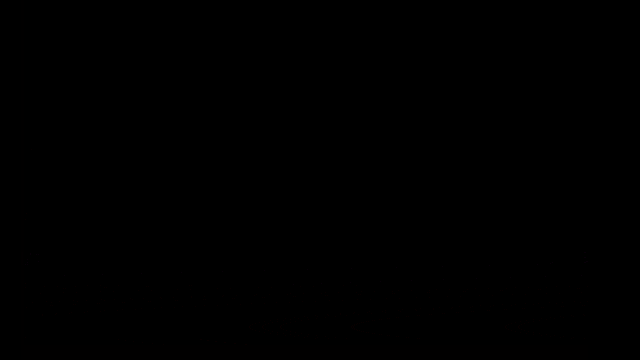
If you’re in a situation where you need to record transactions in your traditional database, but you want a low-latency, flexible, scalable database to power all the interactions leading up to it, Couchbase might be the right fit for you.
Some use cases that Couchbase has been a great fit for include:
-
Product Catalog (Customer spotlight: Tesco)
-
Asset Tracking
-
Content Management (Customer spotlight: replacing SQL Server with Couchbase for content management)
-
Application Configuration
-
Customer Management (Customer spotlight: DirecTV)
-
File or Streaming Metadata Service
-
And many more: check out our whitepaper on top 10 enterprise use cases for NoSQL
Define the success criteria
Once you’ve decided that you have a use case that would be good for Couchbase, you need to define what it means for a proof of concept to be successful.
Examples of criteria:
-
Performance/latency improvements - This might boil down to a number, like "5ms latency in the 95th percentile".
-
Ease of scaling - How easy is it to scale now? How much time does it take a person? How many 2am Saturdays do you need to work to do upgrades?
-
Faster development cycles - Does schema management eat up a lot of time in your sprints? A proof of concept with Couchbase can help to demonstrate if a flexible model is going to save you time.
-
Maintenence and costs
"The most important single aspect of software development is to be clear about what you are trying to build." - Bjarne Stroustrup
— Programming Wisdom (@CodeWisdom) May 6, 2016
Whatever the criteria, it’s good to define it at the beginning, so you can work towards trying to achieve that. A vague goal like "I just want to play around with NoSQL" is fine for an individual developer, but a well-defined success criteria is going to be critical for convincing decision makers.
Understand your data
As I covered in the JSON data modeling post, it’s important for you to understand your data before you even start writing any code. You need to understand what you are going to model and how your application needs to function.
Migrating from a relational to a document database is not going to be a purely mechanical exercise. If you plan to migrate data, it’s better to start by thinking about how it would look independent of how it’s currently stored. Draw out a concept of it on a whiteboard without using "tables" or "documents".
"Weeks of coding can save you hours of planning." - Unknown
— Programming Wisdom (@CodeWisdom) August 22, 2017
Identify the access patterns
I also covered this in my JSON data modeling post. Couchbase is very flexible in the way that it can store data. But, data access is also flexible. The design of your model should take that into account.
"Figure out your data structures, and the code will follow." - William Laeder
— Programming Wisdom (@CodeWisdom) January 24, 2018
In that blog post, I layed out some rules of thumb for nested/seperate documents. At a higher level, you can start with thinking about data access like this:
-
Key/value - The ability to get/change a document based on its key. This is the fastest, lowest latency method available in Couchbase.
-
N1QL query - N1QL is SQL for JSON data, available in Couchbase. It can query data just about any way you can imagine. Most importantly, you can query data based on something other than its key.
-
Full Text Search - When you need to query based on text in a language aware way. Great for user driven searches, for instance.
-
Map/Reduce - Writing a pure function to calculate query results ahead of time. N1QL is taking a lot of the workload away from M/R, but it’s still good for some specialized types of aggregation.
-
Geospatial - Querying of documents based on some geographical/location based information.
-
Analytics/reporting - Couchbase Analytics (currently in preview) can give you heavily indexed non-operational access to your data. You can run complex reports without impacting day-to-day users.
Review the architecure
At the end of your proof of concept, you can measure your results against the criteria that you created at the very beginning.
It might be a good idea to iterate on this proof on concept: you can apply what you’ve leaned in each subsequent iteration. If you keep the iterations short, you can learn what you’ve applied faster. This isn’t just true of Couchbase, by the way, but anything!
"When to use iterative development? You should use iterative development only on projects that you want to succeed." - Martin Fowler
— Programming Wisdom (@CodeWisdom) November 22, 2017
Finally, if your proof of concept is a success (and I know it will be), then it’s time to prepare for production. Take the time to review the architecture, the decisions you’ve made, what worked well, what didn’t work well, and so on. The more you document, the better off the rest of your team and organization will be on the next project.
Summary
Creating a proof of concept with these five steps will help make you successful! All that’s left to do is get started:
-
Download Couchbase Server and try it out today.
-
Post your questions into the Couchbase forum
-
Check out Couchbase’s free online training
-
Contact a Solutions Engineer for resources and help
-
Contact me on Twitter @mgroves if you have any questions or comments (or leave a comment below).
This is a repost that originally appeared on the Couchbase Blog: JSON Data Modeling for RDBMS Users.
JSON data modeling is a vital part of using a document database like Couchbase. Beyond understanding the basics of JSON, there are two key approaches to modeling relationships between data that will be covered in this blog post.
The examples in this post will build on the invoices example that I showed in CSV tooling for migrating to Couchbase from Relational.
Imported Data Refresher
In the previous example, I started with two tables from a relational database: Invoices and InvoicesItems. Each invoice item belongs to an invoice, which is done with a foreign key in a relational database.
I did a very straightforward (naive) import of this data into Couchbase. Each row became a document in a "staging" bucket.

Next, we must decide if that JSON data modeling design is appropriate or not (I don’t think it is, as if the bucket being called "staging" didn’t already give that away).
Two Approaches to JSON data modeling of relationships
With a relational database, there is really only one approach: normalize your data. This means separate tables with foreign keys linking the data together.
With a document database, there are two approaches. You can keep the data normalized or you can denormalize data by nesting it into its parent document.
Normalized (separate documents)
An example of the end state of the normalized approach represents a single invoice spread over multiple documents:
key - invoice::1
{ "BillTo": "Lynn Hess", "InvoiceDate": "2018-01-15 00:00:00.000", "InvoiceNum": "ABC123", "ShipTo": "Herman Trisler, 4189 Oak Drive" }
key - invoiceitem::1811cfcc-05b6-4ace-a52a-be3aad24dc52
{ "InvoiceId": "1", "Price": "1000.00", "Product": "Brake Pad", "Quantity": "24" }
key - invoiceitem::29109f4a-761f-49a6-9b0d-f448627d7148
{ "InvoiceId": "1", "Price": "10.00", "Product": "Steering Wheel", "Quantity": "5" }
key - invoiceitem::bf9d3256-9c8a-4378-877d-2a563b163d45
{ "InvoiceId": "1", "Price": "20.00", "Product": "Tire", "Quantity": "2" }This lines up with the direct CSV import. The InvoiceId field in each invoiceitem document is similar to the idea of a foreign key, but note that Couchbase (and distributed document databases in general) do not enforce this relationship in the same way that relational databases do. This is a trade-off made to satisfy the flexibility, scalability, and performance needs of a distributed system.
Note that in this example, the "child" documents point to the parent via InvoiceId. But it could also be the other way around: the "parent" document could contain an array of the keys of each "child" document.
Denormalized (nested)
The end state of the nested approach would involve just a single document to represent an invoice.
key - invoice::1
{
"BillTo": "Lynn Hess",
"InvoiceDate": "2018-01-15 00:00:00.000",
"InvoiceNum": "ABC123",
"ShipTo": "Herman Trisler, 4189 Oak Drive",
"Items": [
{ "Price": "1000.00", "Product": "Brake Pad", "Quantity": "24" },
{ "Price": "10.00", "Product": "Steering Wheel", "Quantity": "5" },
{ "Price": "20.00", "Product": "Tire", "Quantity": "2" }
]
}Note that "InvoiceId" is no longer present in the objects in the Items array. This data is no longer foreign—it’s now domestic—so that field is not necessary anymore.
JSON Data Modeling Rules of Thumb
You may already be thinking that the second option is a natural fit in this case. An invoice in this system is a natural aggregate-root. However, it is not always straightforward and obvious when and how to choose between these two approaches in your application.
Here are some rules of thumb for when to choose each model:
| If … | Then consider… |
|---|---|
|
Relationship is 1-to-1 or 1-to-many |
Nested objects |
|
Relationship is many-to-1 or many-to-many |
Separate documents |
|
Data reads are mostly parent fields |
Separate document |
|
Data reads are mostly parent + child fields |
Nested objects |
|
Data reads are mostly parent or child (not both) |
Separate documents |
|
Data writes are mostly parent and child (both) |
Nested objects |
Modeling example
To explore this deeper, let’s make some assumptions about the invoice system we’re building.
-
A user usually views the entire invoice (including the invoice items)
-
When a user creates an invoice (or makes changes), they are updating both the "root" fields and the "items" together
-
There are some queries (but not many) in the system that only care about the invoice root data and ignore the "items" fields
Then, based on that knowledge, we know that:
-
The relationship is 1-to-many (a single invoice has many items)
-
Data reads are mostly parent + child fields together
Therefore, "nested objects" seems like the right design.
Please remember that these are not hard and fast rules that will always apply. They are simply guidelines to help you get started. The only "best practice" is to use your own knowledge and experience.
Transforming staging data with N1QL
Now that we’ve done some JSON Data Modeling exercises, it’s time to transform the data in the staging bucket from separate documents that came directly from the relational database to the nested object design.
There are many approaches to this, but I’m going to keep it very simple and use Couchbase’s powerful N1QL language to run SQL queries on JSON data.
Preparing the data
First, create a "operation" bucket. I’m going to transform data and move it to from the "staging" bucket (containing the direct CSV import) to the "operation" bucket.
Next, I’m going to mark the 'root' documents with a "type" field. This is a way to mark documents as being of a certain type, and will come in handy later.
UPDATE staging
SET type = 'invoice'
WHERE InvoiceNum IS NOT MISSING;I know that the root documents have a field called "InvoiceNum" and that the items do not have this field. So this is a safe way to differentiate.
Next, I need to modify the items. They previously had a foreign key that was just a number. Now those values should be updated to point to the new document key.
UPDATE staging s
SET s.InvoiceId = 'invoice::' || s.InvoiceId;This is just prepending "invoice::" to the value. Note that the root documents don’t have an InvoiceId field, so they will be unaffected by this query.
After this, I need to create an index on that field.
Preparing an index
CREATE INDEX ix_invoiceid ON staging(InvoiceId);This index will be necessary for the transformational join coming up next.
Now, before making this data operational, let’s run a SELECT to get a preview and make sure the data is going to join together how we expect. Use N1QL’s NEST operation:
SELECT i.*, t AS Items
FROM staging AS i
NEST staging AS t ON KEY t.InvoiceId FOR i
WHERE i.type = 'invoice';The result of this query should be three total root invoice documents.
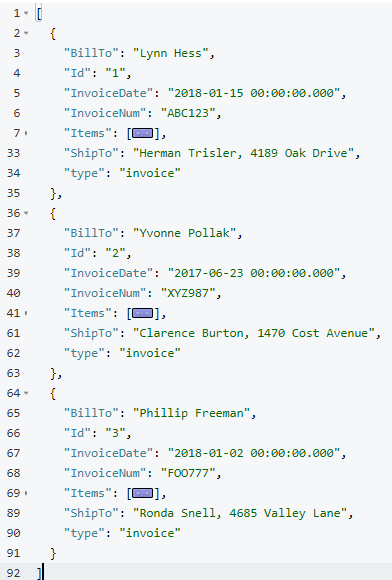
The invoice items should now be nested into an "Items" array within their parent invoice (I collapsed them in the above screenshot for the sake of brevity).
Moving the data out of staging
Once you’ve verified this looks correct, the data can be moved over to the "operation" bucket using an INSERT command, which will just be a slight variation on the above SELECT command.
INSERT INTO operation (KEY k, VALUE v)
SELECT META(i).id AS k, { i.BillTo, i.InvoiceDate, i.InvoiceNum, "Items": t } AS v
FROM staging i
NEST staging t ON KEY t.InvoiceId FOR i
where i.type = 'invoice';If you’re new to N1QL, there’s a couple things to point out here:
-
INSERTwill always useKEYandVALUE. You don’t list all the fields in this clause, like you would in a relational database. -
META(i).idis a way of accessing a document’s key -
The literal JSON syntax being SELECTed AS v is a way to specify which fields you want to move over. Wildcards could be used here.
-
NESTis a type of join that will nest the data into an array instead of at the root level. -
FOR ispecifies the left hand side of theON KEYjoin. This syntax is probably the most non-standard portion of N1QL, but the next major release of Couchbase Server will include "ANSI JOIN" functionality that will be a lot more natural to read and write.
After running this query, you should have 3 total documents in your 'operation' bucket representing 3 invoices.
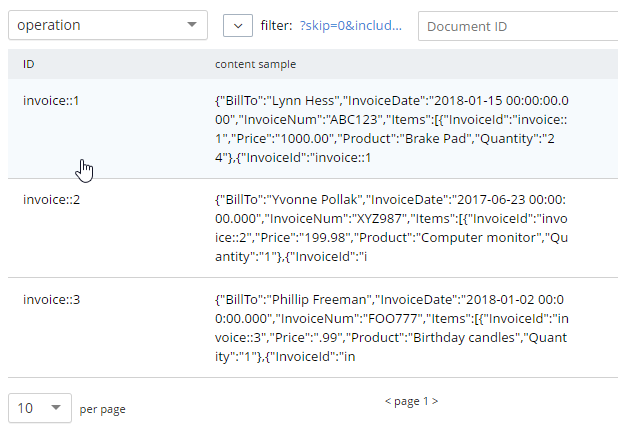
You can delete/flush the staging bucket since it now contains stale data. Or you can keep it around for more experimentation.
Summary
Migrating data straight over to Couchbase Server can be as easy as importing via CSV and transforming with a few lines of N1QL. Doing the actual modeling and making decisions requires the most time and thought. Once you decide how to model, N1QL gives you the flexibility to transform from flat, scattered relational data into an aggregate-oriented document model.
More resources:
-
Using Hackolade to collaborate on JSON data modeling.
-
Part of the SQL Server series discusses the same type of JSON data modeling decisions
-
How Couchbase Beats Oracle, if you’re considering moving some of your data away from Oracle
-
Moving from Relational to NoSQL: How to Get Started white paper.
Feel free to contact me if you have any questions or need help. I’m @mgroves on Twitter. You can also ask questions on the Couchbase Forums. There are N1QL experts there who are very responsive and can help you write the N1QL to accommodate your JSON data modeling.
