
PS C:\Program Files\Couchbase\Server\bin> .\cbexport.exe json -c localhost -u Administrator -p password -b mybucketname -f list -o c:\exportdirectory\cbexporttest.json --include-key _id
Json exported to `c:\exportdirectory\cbexporttest.json` successfully
PS C:\Program Files\Couchbase\Server\bin> type C:\exportdirectory\cbexporttest.json
[
{"_id":"463f8111-2000-48cc-bb69-e2ba07defa37","body":"Eveniet sed unde officiis dignissimos.","type":"Update"},
{"_id":"e39375ab-2cdf-4dc4-9659-6c19b39e377d","name":"Jack Johnston","type":"User"}
]Posts tagged with 'ORM'
Jamie Phillips is writing infrastructure as code. This episode is not sponsored! Want to be a sponsor? You can contact me or check out my sponsorship gig on Fiverr
Show Notes:
-
HCL, and yes it does kinda look like CSS
-
It was just last week, but make sure you don’t miss Jamie’s episode on Packer!
Want to be on the next episode? You can! All you need is the willingness to talk about something technical.
That's right, Cross Cutting Concerns is back for season 3! I know I always say this, but I've got a month full of amazing guests!
I've also got: new original music by JoeFerg (you've gotta hear this!). A new gameshow segment! And much more!
Subscribe now!
Here's what's coming in February:
- Rachel Andrew(!) on CSS Web Grid
- Correl Roush returning to talk Elm
- Tim Wingfield on API design
- Bill Sempf with a very special, jumbo episode discussing information security through the lens of one of my favorite films: Sneakers
Subscribe now with your podcatcher of choice!
Want to be on the next episode? You can! All you need is the willingness to talk about something technical.
This is a repost that originally appeared on the Couchbase Blog: Performance Testing and Load Testing Couchbase with Pillowfight.
Performance testing and load testing are important processes to help you make sure you are production ready. For testing Couchbase Server clusters, there is an open-source command line utility called "cbc-pillowfight". It’s part of libcouchbase.
Before you begin
You’ll need a Couchbase Server cluster up and running. You can try it out directly on your local machine (download Couchbase for Linux, Windows, and Mac) or in a Docker container.
If you’re just trying out pillowfight, you may want to create a bucket on your cluster just for that purpose. I created a bucket called "pillow".
After you have Couchbase Server installed, you’ll need to download and install libcouchbase:
-
Mac:
brew install libcouchbase -
Windows: download a zip file (latest at the time of writing is libcouchbase-2.8.1)
For more information, including Linux instructions, check out the libcouchbase release notes.
Pillow fight for Performance Testing
If you used homebrew to install on a Mac, you can type cbc-pillowfight --help straight away for the command line help screen.
On Windows, unzip the libcouchbase zip file wherever you’d like. You’ll find cbc-pillowfight.exe in the bin folder.
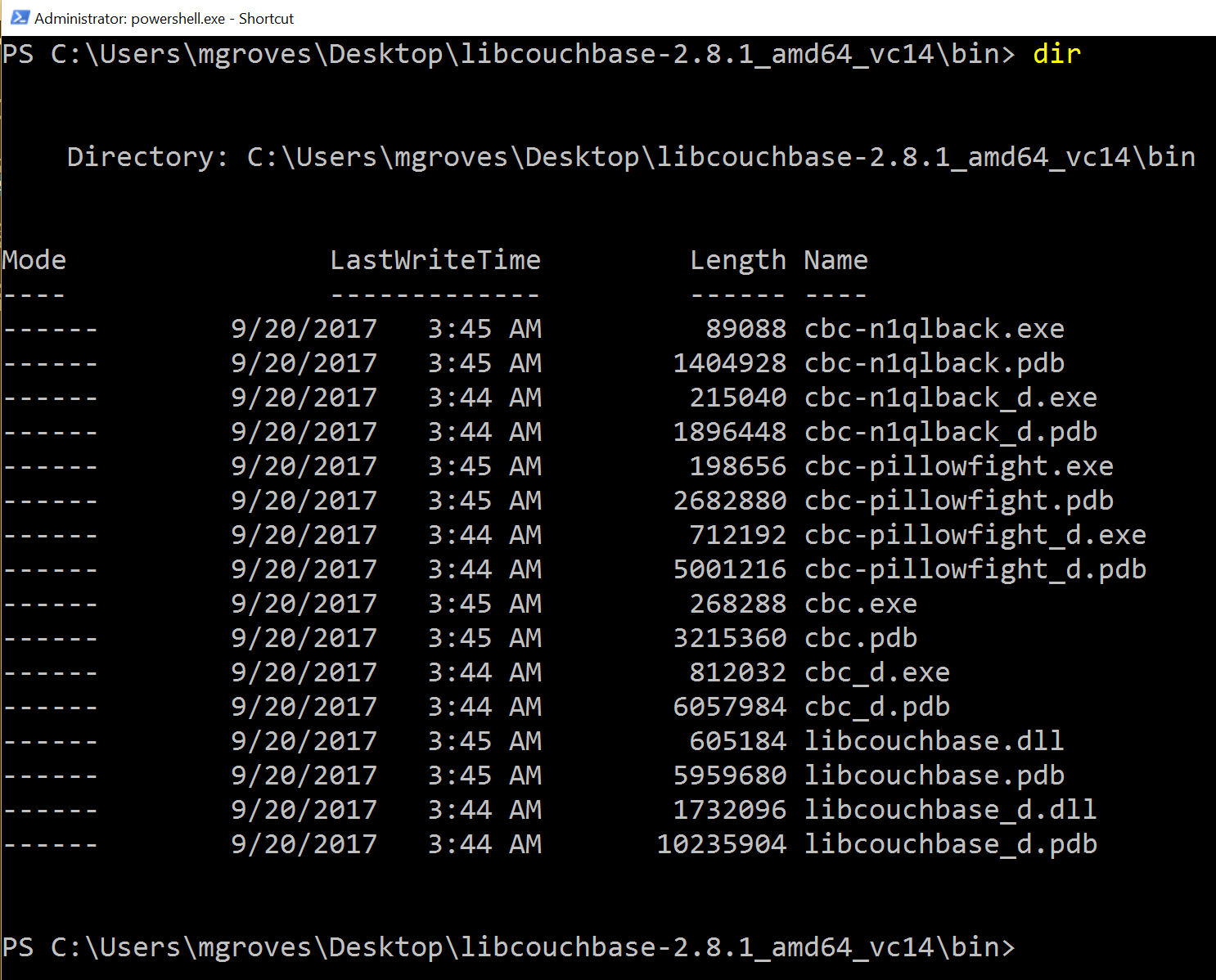
The simplest pillowfight you can run is:
.\cbc-pillowfight.exe -U couchbase://localhost/pillow -u Administrator -P password
This is for a Windows Powershell command line, but it will be very similar on other OSes.
A pillow fight will start for the cluster running on your local machine (localhost), with the "Administrator" user that has a password of "password" (your username and password may be different).
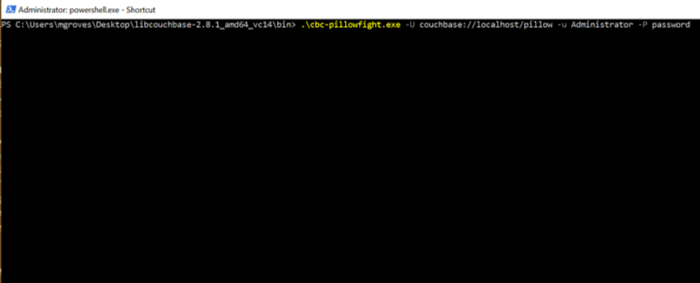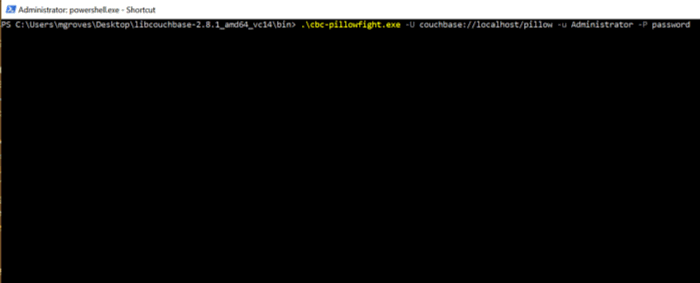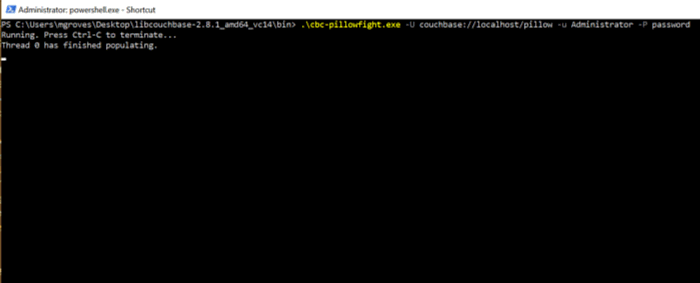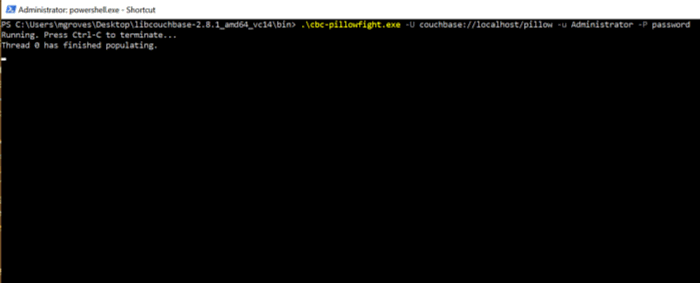
You should see a message like "Thread 0 has finished populating".
What is a pillow fight?
At this point, the pillowfight is going to start creating, updating, and reading documents from the "pillow" bucket. It’s going to do all these operations ("ops") according to the command line settings you specify (or fall back to the defaults).
For instance, with the -I flag, you can specify how many total documents you want to operate on. The default is 1000. So, if you run the above command, you will soon see 1000 documents show up in the pillow bucket.
It doesn’t just create 1000 documents and quit. Pillowfight will keep "getting" and "updating" those documents until you terminate the process. It’s called a "pillowfight" because it will put your Couchbase Cluster into battle (with actual exertion), but it’s really more of a battle simulation.
While the fight is happening, you can monitor bucket statistics to see how your cluster is performing under load.
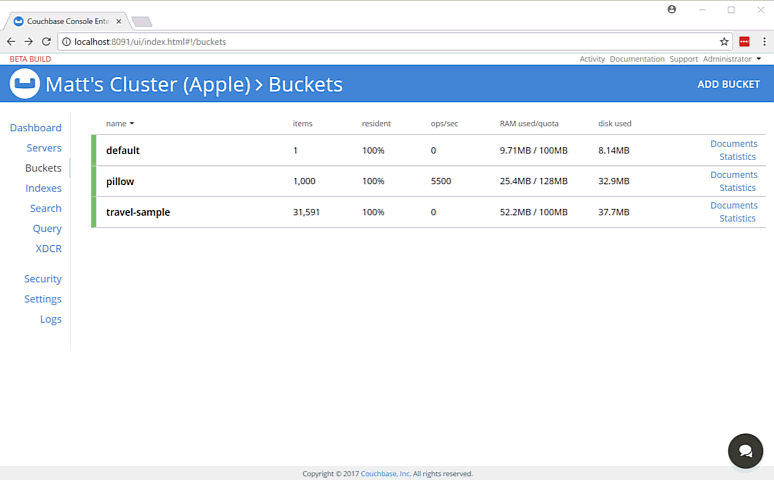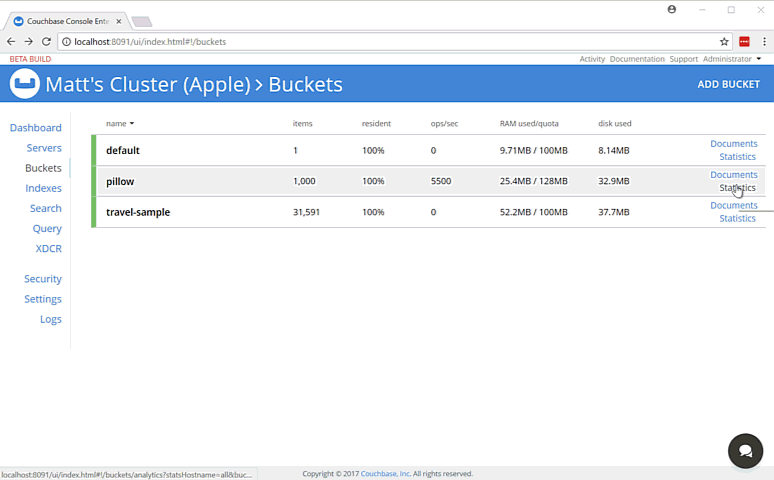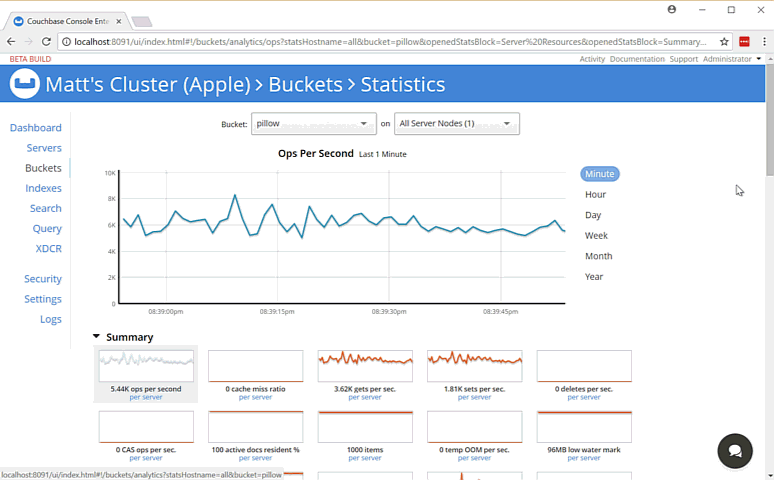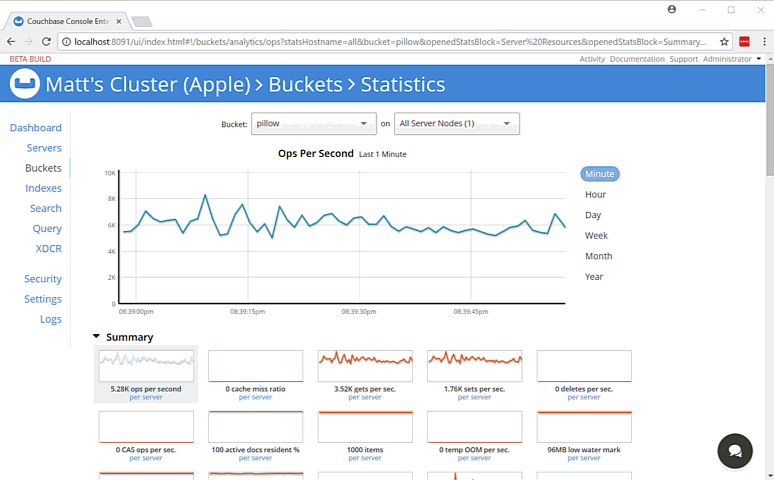
As I type this, the fan on my laptop is whirring to life as I stress test the single node Couchbase cluster that I’ve installed on it. (I suspect my home desktop would create a much more impressive set of charts, but I am traveling a lot this month).
There are a lot of statistics available for you to look at on a bucket level. Check out the Couchbase Server documentation on Monitoring Statistics for more details.
Options for performance testing
The default pillowfight settings may not be optimal for the type of application that you’ll be using with Couchbase. There are many ways to adjust your pillow fight to make it better fit your use cases. For the full list of options, type cbc-pillowfight --help at the command line.
But here are some notable options you might want to try out:
-
-Ior--num-itemswith a number, to specify how many documents you want to operate on. -
--jsonto use JSON payloads in the documents. By default, documents are created with non-JSON payloads, but you may want to have real JSON documents in order to test other aspects of performance while the pillow fight is running. -
-eto expire documents after a certain period of time. If you are using Couchbase as a cache or short term storage, you will want to use this setting to monitor the effect of documents expiring. -
--subdocto use the subdocument API. Not every operation will need to be on an entire document. -
-Mor--max-sizeto set a ceiling on the size of the documents. You may want to adjust this to tailor a more realistic document size for your system. There’s a corresponding-mand--min-sizetoo.
Here’s another example using the above options:
.\cbc-pillowfight.exe -U couchbase://localhost/pillow -u Administrator -P password -I 10000 --json -e 10 --subdoc -M 1024
This will start a pillowfight using 10000 JSON documents, that expire after 10 seconds, uses the sub-document API, and has a max document size of 1024 bytes.
Note: there is a -t --num-threads option. Currently, if you're using Windows (like me), you are limited to a single thread (see this code).
Summary
Couchbase is committed to performance. We do extensive performance testing to make sure that we are delivering the speed you expect. Check out recent blog posts on our Plasma storage engine and N1QL enhancements. But no one knows your use case and infrastructure better than you. With pillowfight, you have a tool to help you do performance testing, load testing, and stress testing.
Thanks go out to Sergey Avseyev for helping with this blog post, and his contributions to libcouchbase.
Please reach out with questions on Couchbase by leaving a comment below or finding me on Twitter @mgroves.
This is a repost that originally appeared on the Couchbase Blog: Tooling Improvements in Couchbase 5.0 Beta.
Tooling improvements have come to Couchbase Server 5.0 Beta. In this blog post, I’m going to show you some of the tooling improvements in:
-
Query plan visualization - to better understand how a query is going to execute
-
Query monitoring - to see how a query is actually executing
-
Improved UX - highlighting the new Couchbase Web Console
-
Import/export - the new cbimport and cbexport tooling
Some of these topics have been covered in earlier blog posts for the developer builds (but not the Beta). For your reference:
Query Plan Visualization tooling
In order to help you write efficient queries, the tooling in Couchbase Server 5.0 has been enhanced to give you a Visual Query Plan when writing N1QL queries. If you’ve ever used the Execution Plan feature in SQL Server Management Studio, this should feel familiar to you.
As a quick example, I’ll write a UNION query against Couchbase’s travel-sample bucket (optional sample data that ships with Couchbase Server). First, I’ll click "Query" to bring up the Couchbase Query Workbench. Then, I’ll enter a query into the Query Editor.
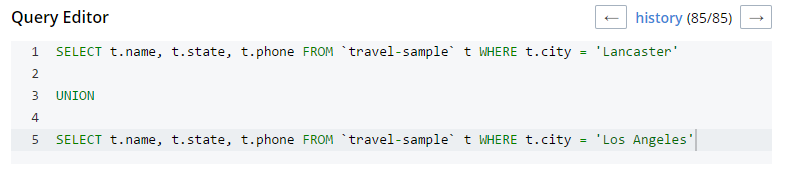
This is a relatively complex query that involves the following steps (and more):
-
Identify and scan the correct index(es)
-
Fetch the corresponding data
-
Project the fields named in the
SELECTclause -
Find distinct results
-
UNIONthe results together -
Stream the results back to the web console
In Couchbase Server 4.x, you could use the EXPLAIN N1QL command to get an idea of the query plan. Now, in Couchbase Server 5.0 beta, you can view the plan visually.
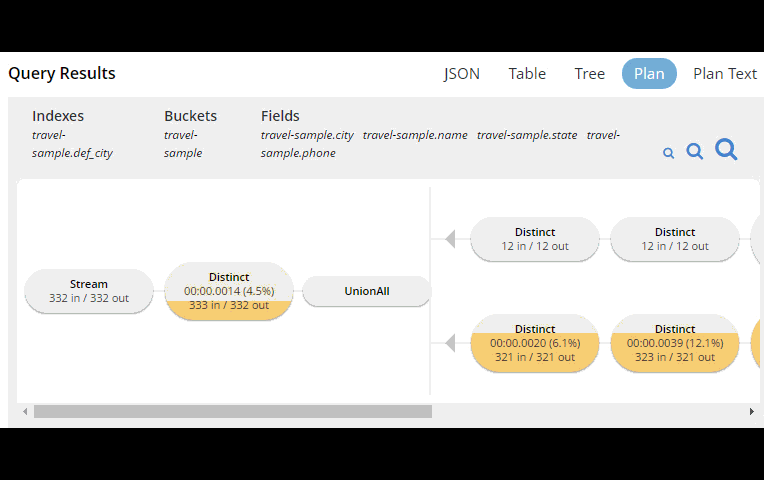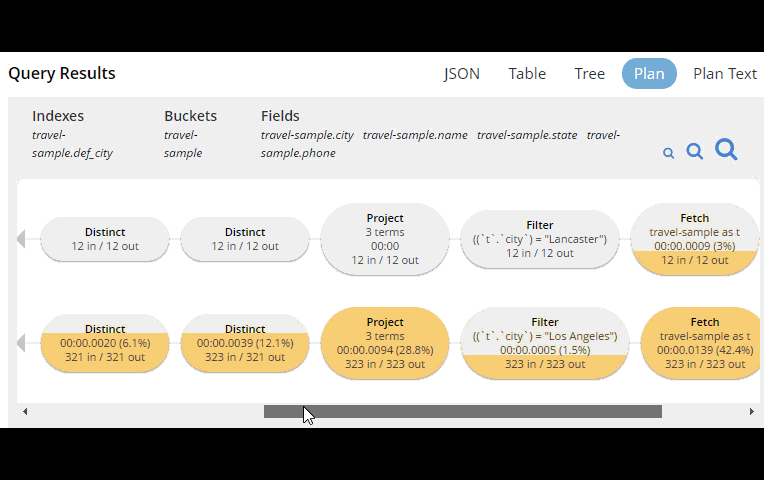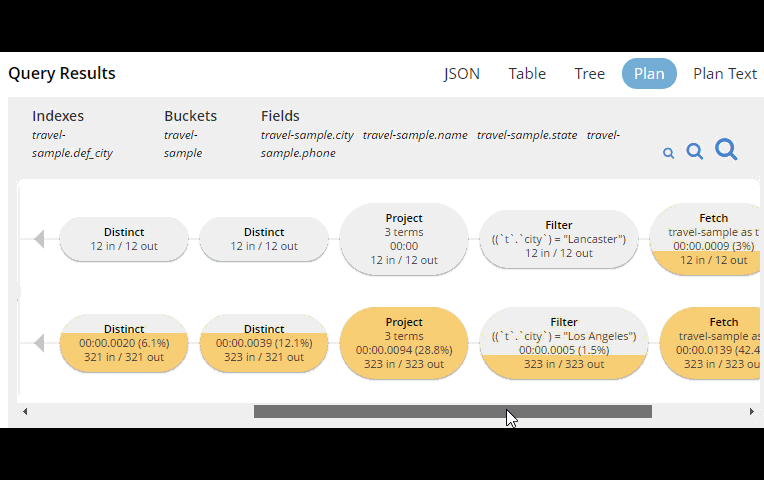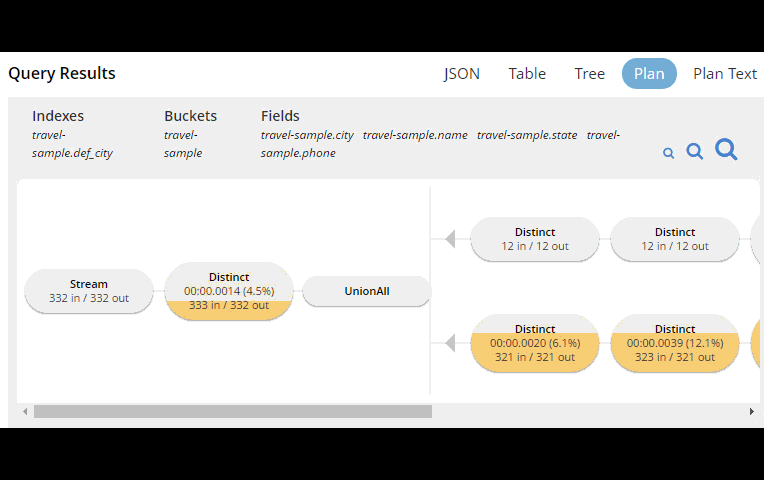
This tooling shows you, at a glance, the costliest parts of the query, which can help you to identify improvements.
Query monitoring
It’s important to have tooling to monitor your queries in action. Couchbase Server 5.0 beta has tooling to monitor active, completed, and prepared queries. In addition, you have the ability to cancel queries that are in progress.
Start by clicking "Query" on the Web Console menu, and then click "Query Monitor". You’ll see the "Active", "Completed", and "Prepared" options at the top of the page.
Let’s look at the "Completed" queries page. The query text and other information about the query is displayed in a table.

Next, you can sort the table to see which query took the longest to run (duration), return the most results (result count), and so on. Finally, if you click "edit", you’ll be taken to the Query Workbench with the text of that query.
New Couchbase Web Console
If you’ve been following along, you’ve probably already noticed the new Couchbase Web Console. The UI has been given an overhaul in Couchbase Server 5.0. The goal is to improve navigation and optimize the UI.
This new design maximizes usability of existing features from Server 4.x, while leaving room to expand the feature set of 5.0 and beyond.
cbimport and cbexport
New command line tooling includes cbimport and cbexport for moving data around.
cbimport supports importing both CSV and JSON data. The documentation on cbimport should tell you all you want to know, but I want to highlight a couple things:
-
Load data from a URI by using the
-d,--dataset <uri>flags -
Generate keys according to a template by using the
-g,--generate-key <key_expr>flags. This gives you a powerful templating system to generate unique keys that fit your data model and access patterns -
Specify a variety of JSON formats when importing: JSON per line (
lines), JSON list/array (list), JSON ZIP file/folder containing multiple files (sample). So no matter what format you receive JSON in, cbimport can handle it.
For more about cbimport in action, check out Using cbimport to import Wikibase data to JSON documents.
cbexport exports data from Couchbase to file(s). Currently, only the JSON format is supported. Again, the documentation on cbexport will tell you what you want to know. A couple things to point out:
-
Include the document key in your export by using the
--include-key <key>flag. -
Export to either "lines" or "list" format (see above).
Here’s an example of cbexport in action (I’m using Powershell on Windows, but it will be very similar on Mac/Linux):
Notice that the key was included in an "_id" field.
Summary
Tooling for Couchbase Server 5.0 beta is designed to make your life easier. These tools will help you whether you’re writing queries, integrating with data, monitoring, or performing administrative tasks.
We’re always looking for feedback. Inside of the Web Console, there is a feedback icon at the bottom right of the screen. You can click that to send us feedback about the tooling directly. Or, feel free to leave a comment below, or reach out to me on Twitter @mgroves.
I took a long break from ORMs in my career: about 4 years. I was working on a reporting product, and an ORM is just the wrong tool for that. Before that, I worked with ORMs here and there: NHibernate and another ORM I don't even want to mention by name for fear of being associated with it in public. For some of my own projects like the next version of EZRep and this very blog site, I've switched to a so-called micro-ORM, specifically Dapper.
Now that I'm back to consulting, I'm back into the ORM game. This time, it's Entity Framework. Early in this project (that uses EF), I've been experiencing quite a bit of frustration. It seems like I'm swimming upstream while jumping through hoops to accomplish really simple things that wouldn't take nearly as much work in Dapper. Maybe this is just me getting back into the habit, but it's also got me thinking: why do I really need a "full" ORM anymore? Abstraction and indirection are important tools, but perhaps full ORMs aren't the least leaky abstraction anymore in many cases?
Yes, a full ORM is sometimes RTRJ. However, I think micro ORMs (Dapper, PetaPoco, Massive) and document databases (Raven, Couch, Mongo) have taken a big bite out of the pool of possible use cases, and that a lot of full ORM and/or RDBMS usage in projects is really used not because it's the best tool, but because of the sheer momentum of the status quo. Imagine a snapshot of a Venn diagram taken 5 or 10 years ago compared to one I made up to represent a snapshot of today.
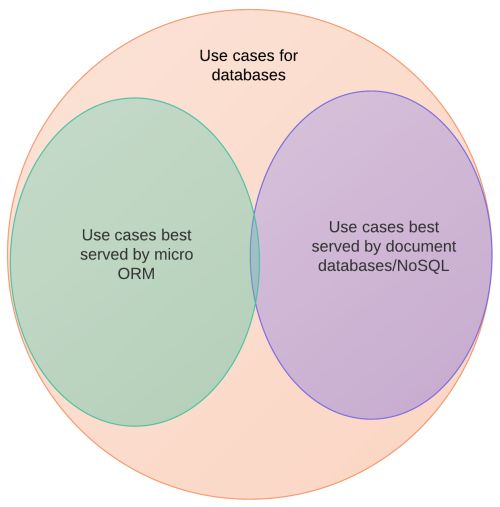
There might be missing bubbles like "RDBMS + no ORM" or "Json string in text file", and the exact proportions are open to interpretation. But the point I'm trying to make is this: the number of use cases that are best served by RDBMS + full ORM is shrinking, and will continue to shrink.
