Posts tagged with 'csharp'
I've heard some talk on twitter, blogs, and at various user groups and conferences for a while now about using the command/query object pattern instead of the repository pattern for a data access layer, and all the benefits of doing so.
So, I decided to explore it for myself. I converted over my Ledger project, since it used repositories, has some complexity, but is not particularly large.
Ledger already uses Dapper, so I started with Dustin Brown's post on using command/query with Dapper. For the most part, I followed what he did exactly (I also had to finally get Ledger using an IoC container, which I had been putting off for a while). These are the four files I used to get started with the pattern:
Note that mine differs from Dustin's only in that his IDatabase contains two methods named Execute, whereas mine contains one named Query and one named Execute. Note that except for IDatabase, these all depend on System.Data.IDbConnection (which is what Dapper uses). So, if you want to use a different DB access library, you'll have to change these.
Now, you need to create queries and/or commands. A query returns data, a command manipulates data. Here's a command that uses Dapper to create a new ledger:
Note that the information for the new ledger is passed via a constructor. And here's an example of a query that returns a single ledger, given an ID number (note that the ID is a constructor parameter).
Here's an example of both of those command/query objects in action inside of a controller.
That's the mechanics of it. It was much simpler to code than it might sound.
I don't know if I'm ready to draw any definitive conclusions about this pattern yet, but here are my thoughts:
- I'm not particulary happy with the ceremony involved when doing this in C#. Compared to repository, it's a bit of extra noise and typing to use Execute + new keyword + constructor parameters + private fields to hold arguments.
- Organizationally, I don't have to think about which method goes to which repository anymore. Organization, then, is strictly a matter of folders and/or namespace, and changing those is not as costly. I like that.
- I also like that instead of 2, 3, or even more repositories, I only need one IDatabase member in my controller.
- I haven't gone hands-on with unit testing, but I don't anticipate it being much harder. I could also forsee that this pattern is less likely to result in broken tests when making changes to a repository's interface.
I am impressed, but I am not entirely convinced yet. I think this may need further research, especially when it comes to unit tests.
Welcome to another "Weekly Concerns". This is a post-a-week series of interesting links, relevant to programming and programmers. You can check out previous Weekly Concerns posts in the archive.
- I've been exploring the Command/Query Objects pattern, specifically with the idea of replacing the repository pattern. I've started with Dustin's Brown post about Command/Query Objects with Dapper.
- How to setup Twitter Cards for your site (specifically WordPress, but blog post is helpful for everyone else too).
- Rob Gibbens posted about using Fody.PropertyChanged (an AOP plugin to the Fody IL rewriting framework) with Xamarin to use the MVVM pattern.
- EconTalk is one of my favorite podcasts. Check out this episode about the "sharing economy", in which they discuss the impact of technology like Uber, AirBnb, and so on, featuring my favorite guest: Michael Munger. Especially interesting to me is the discussion about taxi medallion investments.
If you have an interesting link that you'd like to see in Weekly Concerns, leave a comment or contact me.
We take the internet for granted. I can send information to just about anyone without a stamp, without ink, without waiting for a truck to come pick it up.
However, some parts of the world are still mired in actual paper work, for whatever reason: legal lag, technology costs, fear of change, etc. So, despite the fact that I can book a hotel, refill my prescriptions, start an LLC, and a thousand other things over the web, there are often times where I still have to send faxes, sign documents with a pen, and lick envelopes.
I have come up with some ways of insulating myself from some of these primitive forms of communication. Often this means I have to take a PDF, print out one page, sign it, scan it, and then reconstruct that PDF. Or, with an expense report, I'll take multiple scans/photos of receipts and have to stitch them together into one PDF. A long time ago, I couldn't figure out how to actually stitch PDFs together into one document without something like Adobe Acrobat installed (which I don't want to buy and don't want to install). So, I created a little tool that I called MattDoc.
I called it that because it needed a name and I was in a hurry (as you'll see by the interface). I have decided to make this tool open source, as part of my ongoing code garage sale.
Here's how it works. Suppose I have three PDF files: page1.pdf, page2.pdf, and page3.pdf. I want a single PDF that consists of these three documents in series. I click "Browse" to add each file, in order. Then I click "Save to 1 PDF". PdfSharp does the work here. It also works with images.
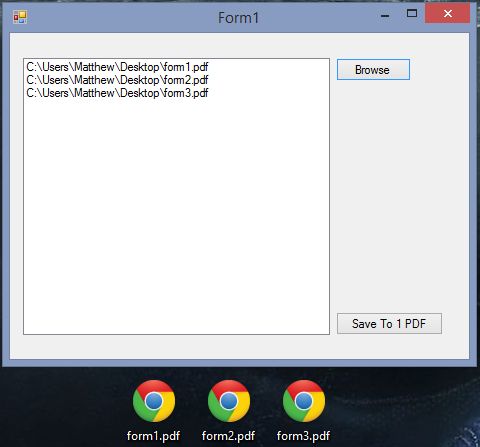
The UI is very unpolished. It could use some work, and a couple more features (for instance, right now there's no way to reorder or remove files from the list).
Hopefully this will help you stitch documents together (or maybe there's a much easier way that I don't know about) or maybe this will help you try out PdfSharp for the first time.
P.S. If you check out the git history, you'll see that I wrote this before NuGet was really a thing (or at least a thing I knew how to use): I've been using it and getting value out of it that long.
Welcome to another "Weekly Concerns". This is a post-a-week series of interesting links, relevant to programming and programmers. You can check out previous Weekly Concerns posts in the archive.
- 5 Things You Should Stop Doing With jQuery. It's a sensational title, but read all the way to the end before you judge.
- PostSharp 3.2 Preview 2 is available, with improvements that help you write multi-threaded code (among other things).
- Direct casting vs "as" casting in C#
- Check out the new and improved WordPress Code Reference.
If you have an interesting link that you'd like to see in Weekly Concerns, leave a comment or contact me.
I've recently wrapped up work on a project, so I thought I'd share what I've learned, specifically in regards to Fluent Migrator (which I introduced in a previous post).
Mostly, it went pretty good, but there were a few bumps along the way, and a few things that still aren't as elegant as I'd like. As always, your mileage may vary.
1) Fluent Migrator and Entity Framework do okay together. I'm sure that Entity Framework Code First Migrations probably make a little more sense, but this project wasn't exactly using EF in a textbook fashion anyway.
2) Fluent Migrator works great with Octopus Deploy. But maybe not for rolling back. I've found that rolling back is typically something I only do when I'm developing. By the time I check in a migration, it's pretty much not getting rolled back, and certainly not by Octopus. There are a handful of migrations where a rollback doesn't really work anyway (how do you rollback making a varchar field bigger, for instance?) So, my thought with rollbacks is: do the best you can, don't worry if your rollbacks aren't perfect, and after the migration is committed and/or deployed, consider "rolling forward" instead of rolling back.
3) Fluent Migrator is great for tables. It is not so great with views/sprocs/functions/etc. I didn't really have a plan for these when I started. Fluent Migrator can use embedded script files--that's the direction I went with it. But I'm not terribly happy with it: seems like a lot of repetition and/or ambiguity.
4) Similarly, I didn't have a plan in place for dealing with test data or sprocs/views that use linked servers. I explored using profiles for these, but again, I'm not terribly pleased with the result. I think, generally, it would be nicer to avoid the views/sprocs as much as possible.
5) My strategy of creating a bunch of bat files is okay, but it would be really nice if there was some sort of little UI tool for running migrations. Something where I could select (or enter) a connection string, specify a couple of flags with dropdowns/checkboxes/etc, and a button to run the migration. I think this would be preferable to having to look up all the command line flags each time (which I did often enough to annoy me, but not often enough to commit them to memory) and/or save a whole bunch of batch file variations. Maybe a standalone WinForms app, or maybe a VS plugin.
I think one of the challenges with Fluent Migrator was demonstrating its value to the rest of the team at the beginning. It seemed like a lot of extra and/or unnecessary work and bookkeeping. However, once we got a build server and deployment server running, it really paid off. Deployments became much easier: there was no more asking around and trying to figure out which versions of the database were being put where. It was one less strain towards the end of each sprint.
