

SELECT r.destinationairport, r.sourceairport, r.distance, r.airlineid, a.name
FROM `travel-sample` r
JOIN `travel-sample` a ON KEYS r.airlineid
WHERE r.type = 'route'
AND r.sourceairport = 'CMH'
ORDER BY r.distance DESC
LIMIT 10;Posts tagged with 'c'
Andrea Cremese is building and using Saas.
Show Notes:
-
The Henry Ford quote appears to be apocryphal: Henry Ford, Innovation, and That “Faster Horse†Quote
-
Podcast: The Top by Nathan Latka
-
Interview with Aaron Levy, the CEO of box
-
Movie: Abacus: small enough to jail
Want to be on the next episode? You can! All you need is the willingness to talk about something technical.
Music is by Joe Ferg, check out more music on JoeFerg.com!
Jeffrey Miller is using Neo4j. This episode is sponsored by Smartsheet.
Show Notes:
-
CosmosDB on Azure
-
Magic: The Gathering is a collectible card game that I once sunk a lot of money into
-
Michael Hunger developer relations with Neo4j
-
link: Presentation slides by Jeffrey
Want to be on the next episode? You can! All you need is the willingness to talk about something technical.
Music is by Joe Ferg, check out more music on JoeFerg.com!
This is a repost that originally appeared on the Couchbase Blog: New Querying Features in Couchbase Server 5.5.
New querying features figure prominently in the latest release of Couchbase Server 5.5. Check out the announcement and download the developer build for free right now.
In this post, I want to highlight a few of the new features and show you how to get started using them:
-
ANSI JOINs - N1QL in Couchbase already has JOIN, but now JOIN is more standards compliant and more flexible.
-
HASH joins - Performance on certain types of joins can be improved with a HASH join (in Enterprise Edition only)
-
Aggregate pushdowns - GROUP BY can be pushed down to the indexer, improving aggregation performance (in Enterprise Edition only)
All the examples in this post use the "travel-sample" bucket that comes with Couchbase.
ANSI JOINs
Until Couchbase Server 5.5, JOINs were possible, with two caveats:
-
One side of the JOIN has to be document key(s)
-
You must use the
ON KEYSsyntax
In Couchbase Server 5.5, it is no longer necessary to use ON KEYS, and so writing joins becomes much more natural and more in line with other SQL dialects.
Previous JOIN syntax
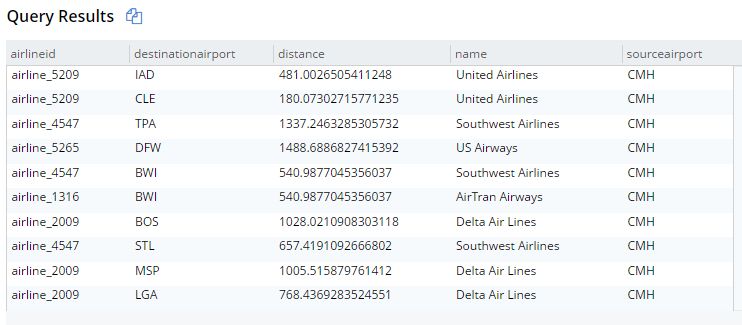
For example, here’s the old syntax:
This will get 10 routes that start at CMH airport, joined with their corresponding airline documents. The result are below (I’m showing them in table view, but it’s still JSON):
New JOIN syntax
And here’s the new syntax doing the same thing:
SELECT r.destinationairport, r.sourceairport, r.distance, r.airlineid, a.name
FROM `travel-sample` r
JOIN `travel-sample` a ON META(a).id = r.airlineid
WHERE r.type = 'route'
AND r.sourceairport = 'CMH'
ORDER BY r.distance DESC
LIMIT 10;The only difference is the ON. Instead of ON KEYS, it’s now ON <field1> = <field2>. It’s more natural for those coming from a relational background (like myself).
But that’s not all. Now you are no longer limited to joining just on document keys. Here’s an example of a JOIN on a city field.
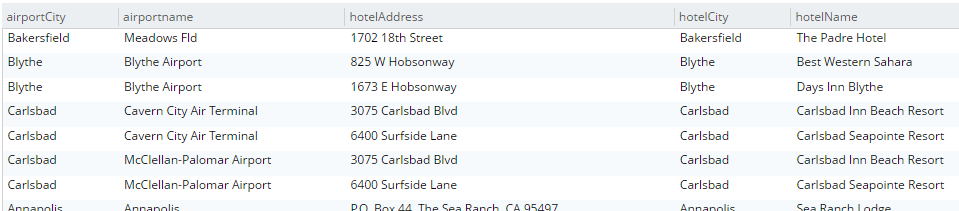
SELECT a.airportname, a.city AS airportCity, h.name AS hotelName, h.city AS hotelCity, h.address AS hotelAddress
FROM `travel-sample` a
INNER JOIN `travel-sample` h ON h.city = a.city
WHERE a.type = 'airport'
AND h.type = 'hotel'
LIMIT 10;This query will show hotels that match airports based on their city.
Note that for this to work, you must have an index created on the field that’s on the inner side of the JOIN. The "travel-sample" bucket already contains a predefined index on the city field. If I were to attempt it with other fields, I’d get an error message like "No index available for ANSI join term…".
For more information on ANSI JOIN, check out the full N1QL JOIN documentation.
Note: The old JOIN, ON KEYS syntax will still work, so don’t worry about having to update your old code.
Hash Joins
Under the covers, there are different ways that joins can be carried out. If you run the query above, Couchbase will use a Nested Loop (NL) approach to execute the join. However, you can also instruct Couchbase to use a hash join instead. A hash join can sometimes be more performant than a nested loop. Additionally, a hash join isn’t dependent on an index. It is, however, dependent on the join being an equality join only.
For instance, in "travel-sample", I could join landmarks to hotels on their email fields. This may not be the best find to find out if a hotel is a landmark, but since email is not indexed by default, it illustrates the point.
SELECT l.name AS landmarkName, h.name AS hotelName, l.email AS landmarkEmail, h.email AS hotelEmail
FROM `travel-sample` l
INNER JOIN `travel-sample` h ON h.email = l.email
WHERE l.type = 'landmark'
AND h.type = 'hotel';The above query will take a very long time to run, and probably time out.
Syntax
Next I’ll try a hash join, which must be explicitly invoked with a USE HASH hint.
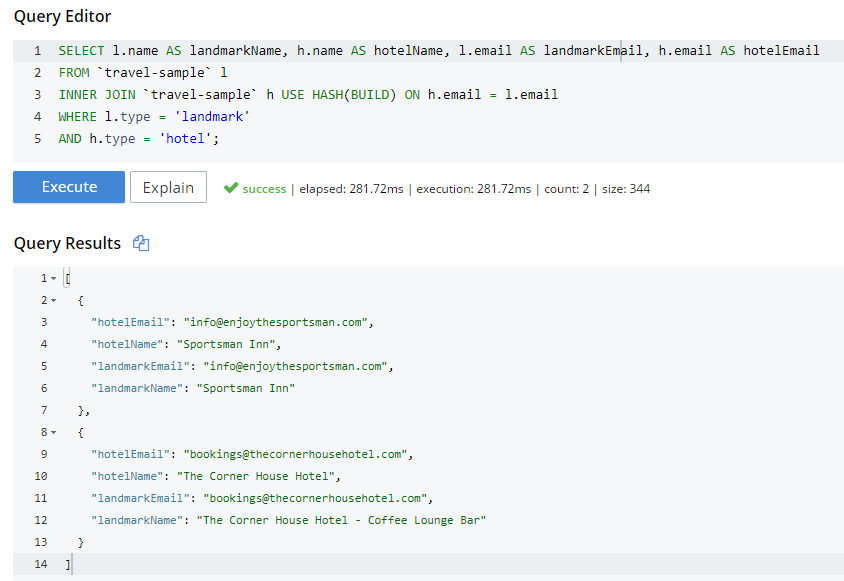
SELECT l.name AS landmarkName, h.name AS hotelName, l.email AS landmarkEmail, h.email AS hotelEmail
FROM `travel-sample` l
INNER JOIN `travel-sample` h USE HASH(BUILD) ON h.email = l.email
WHERE l.type = 'landmark'
AND h.type = 'hotel';A hash join has two sides: a BUILD and a PROBE. The BUILD side of the join will be used to create an in-memory hash table. The PROBE side will use that table to find matches and perform the join. Typically, this means you want the BUILD side to be used on the smaller of the two sets. However, you can only supply one hash hint, and only to the right side of the join. So if you specify BUILD on the right side, then you are implicitly using PROBE on the left side (and vice versa).
BUILD and PROBE
So why did I use HASH(BUILD)?
I know from using INFER and/or Bucket Insights that landmarks make up roughly 10% of the data, and hotels make up about 3%. Also, I know from just trying it out that HASH(BUILD) was slightly slower. But in either case, the query execution time was milliseconds. Turns out there are two hotel-landmark pairs with the same email address.
USE HASH will tell Couchbase to attempt a hash join. If it cannot do so (or if you are using Couchbase Server Community Edition), it will fall back to a nested-loop. (By the way, you can explicitly specify nested-loop with the USE NL syntax, but currently there is no reason to do so).
For more information, check out the HASH join areas of the documentation.
Aggregate pushdowns
Aggregations in the past have been tricky when it comes to performance. With Couchbase Server 5.5, aggregate pushdowns are now supported for SUM, COUNT, MIN, MAX, and AVG.
In earlier versions of Couchbase, indexing was not used for statements involving GROUP BY. This could severely impact performance, because there is an extra "grouping" step that has to take place. In Couchbase Server 5.5, the index service can do the grouping/aggregation.
Example
Here’s an example query that finds the total number of hotels, and groups them by country, state, and city.
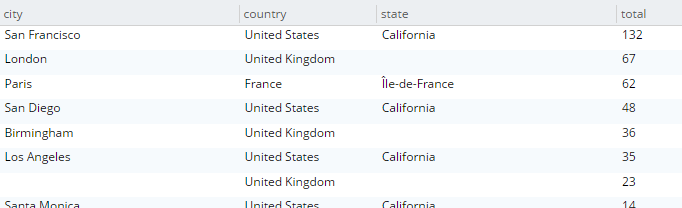
SELECT country, state, city, COUNT(1) AS total
FROM `travel-sample`
WHERE type = 'hotel' and country is not null
GROUP BY country, state, city
ORDER BY COUNT(1) DESC;The query will execute, and it will return as a result:
Let’s take a look at the visual query plan (only available in Enterprise Edition, but you can view the raw Plan Text in Community Edition).

Note that the only index being used is for the type field. The grouping step is doing the aggregation work. With the relatively small travel-sample data set, this query is taking around ~90ms on my single node desktop. But let’s see what happens if I add an index on the fields that I’m grouping by:
Indexing
CREATE INDEX ix_hotelregions ON `travel-sample` (country, state, city) WHERE type='hotel';Now, execute the above SELECT query again. It should return the same results. But:
-
It’s now taking ~7ms on my single node desktop. We’re taking ms, but with a large, more realistic data set, that is a huge difference in magnitude.
-
The query plan is different.

Note that this time, there is no 'group' step. All the work is being pushed down to the index service, which can use the ix_hotelregions index. It can use this index because my query is exactly matching the fields in the index.
Index push down does not always happen: your query has to meet specific conditions. For more information, check out the GROUP BY and Aggregate Performance areas of the documentation.
Summary
With Couchbase Server 5.5, N1QL includes even more standards-compliant syntax and becomes more performant than ever.
Try out N1QL today. You can install Enterprise Edition or try out N1QL right in your browser.
Have a question for me? I’m on Twitter @mgroves. You can also check out @N1QL on Twitter. The N1QL Forum is a good place to go if you have in-depth questions about N1QL.

Scott Drake is hiring programmers. This episode is sponsored by Smartsheet.
Show Notes:
-
CodeStock is April 20-21 in Knoxville, TN
-
CodePaLOUsa is in Louisville, KY, March 28-30th.
-
Book: Multipliers by Liz Wiseman
-
Blog post: 8 Factors That Reveal if a Programmer Will Fit Your Team and Organization
-
Book: Drive by Daniel Pink
Want to be on the next episode? You can! All you need is the willingness to talk about something technical.
Music is by Joe Ferg, check out more music on JoeFerg.com!
Stephen Cleary is writing Azure Functions. This episode is sponsored by Smartsheet.
Show Notes:
-
The Stack Overflow answer that prompted this podcast
-
Be sure to check out
LazyThreadSafetyModein the documentation (Stephen recommendedPublicationOnlymode) -
Stephen’s AsyncEx project
-
Jon Skeet’s EduAsync series
-
Microsoft docs on Azure Functions
-
Spend some time with your family!
Want to be on the next episode? You can! All you need is the willingness to talk about something technical.
Music is by Joe Ferg, check out more music on JoeFerg.com!
